
GPU Driven Rendering (四)

【SIGGRAPH 2021】Geometry Rendering Pipeline Architecture
这篇文章是动视暴雪在2021年的分享,主要介绍引擎处理场景中大量复杂的geometry的渲染,提出了一套geometry processing pipeline。

从小场景转向开放世界后,场景中需要处理的三角形数量大幅度增加,达到800多万,这意味在引擎和目标平台不变的情况下,三角形的数量翻了整整十倍。场景中不仅模型数量众多,而且网格mesh的密度也很大。

动视旗下的游戏拥有多款经过优化的不同的渲染引擎,支持包括Forward+(F+), Deferred, Visibility+(V+)等渲染管线。
- Forward+ : 着色在几何绘制阶段完成,所有顶点的数据从VS阶段直接传递到PS阶段,并由PS着色器完成着色计算。
- Deferred : 着色分为两个阶段,在GBUFFER阶段执行vs-ps管线,生成BRDF所需要的所有的参数并保存为GBuffer Texture;然后是计算着色阶段,读取GBUFFER完成统一的着色计算。
- Visibility+: 将几何于着色分离,通过逐个像素存储三角形和顶点引用或者材质id,在后续通过计算着色器完成BRDF着色计算。
经过测试发现,处理大尺寸三角形(quad占用率大于75%)时,deferred性能最差,而V+的性能接近于F+, 而处理超高面数网格时,Deferred的性能就要大于F+的性能,而V+的性能可以和Deferred性能持平,在材质复杂度提升时,V+的优势会超过Deferred。

比较了不同的渲染方式的优缺点,最终决定的方式是采用F+和V+的混合渲染管线,对于普通密度的网格,负责的顶点格式以及可形变的几何体,采用F+的管线;而对于高密度的网格以及简单的顶点格式,则采用V+的管线。
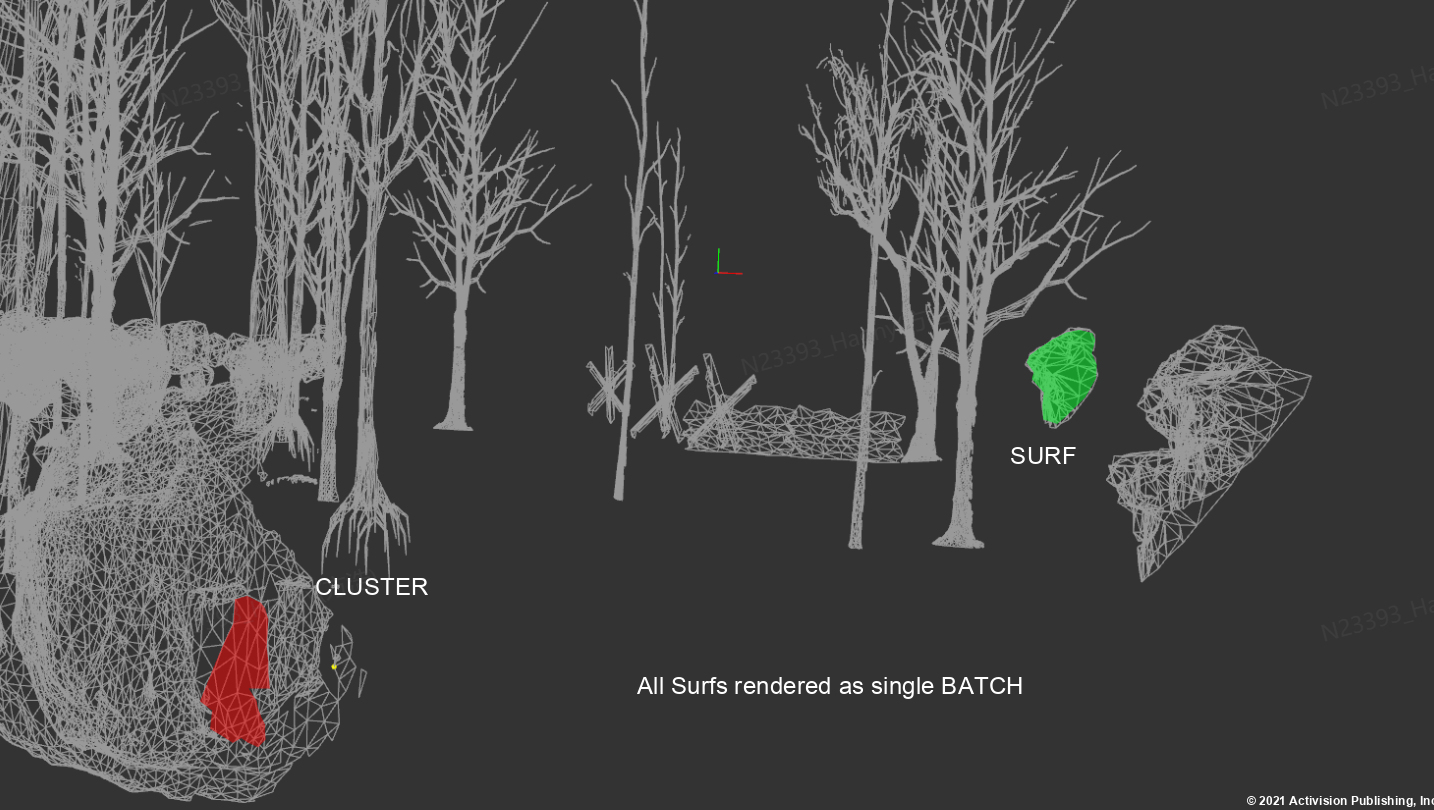
这里会首先将场景进行层级的划分,分为BATCH - SURF - CLUSTER三个层级,其中每个Batch对应一个DrawCommand,包括drawIndirect和drawIndexIndirect;一个Batch由若干个Surf组成,每个Surf则是表示每个mesh的一部分,mesh按照不可合并的material划分为若干个Surf,每个surf内的三角形的材质是一致的;每个Surf又由若干个Cluster组成,每个cluster则是一个64个三角形的strip。

为了能够实现完整的GPU Driven Pipeline,需要几个部分的工作。
首先是我们需要一个叫做UGB的Unified Geometry Buffers来保存所有的geometry数据,从而一个drawcall就可以绘制所有网格。
其次我们需要将原始的mesh都提前划分为triangle clusters的表达,用于后续的管线处理。
最后我们需要将所有的工作单元划分为层级结构,支持任务扩展,能够在渲染的各个阶段之间执行间接剔除,让GPU可以动态调制任务规模,只处理可见的几何数据。
Unified Geometry Buffers

UGB是一个面向所有的几何数据的虚拟内存池,它的核心作用是绕开传统的顶点数据流和顶点装配,采用软件手动解析顶点数据。支持更加自由的数据打包。对于每个surf,会在UGB中记录一个数据偏移量base offset,然后根据offset和vertexId来获取顶点数据。程序化生成的数据也会存储到UGB中,使用统一的顶点数据访问接口。这种通过软件手动解析顶点数据的方式可以省去frontend的顶点处理相关的api调用,减少CPU的负载压力。UGB还支持LOD的自主管理和不同层级的LOD drawcall的合并。
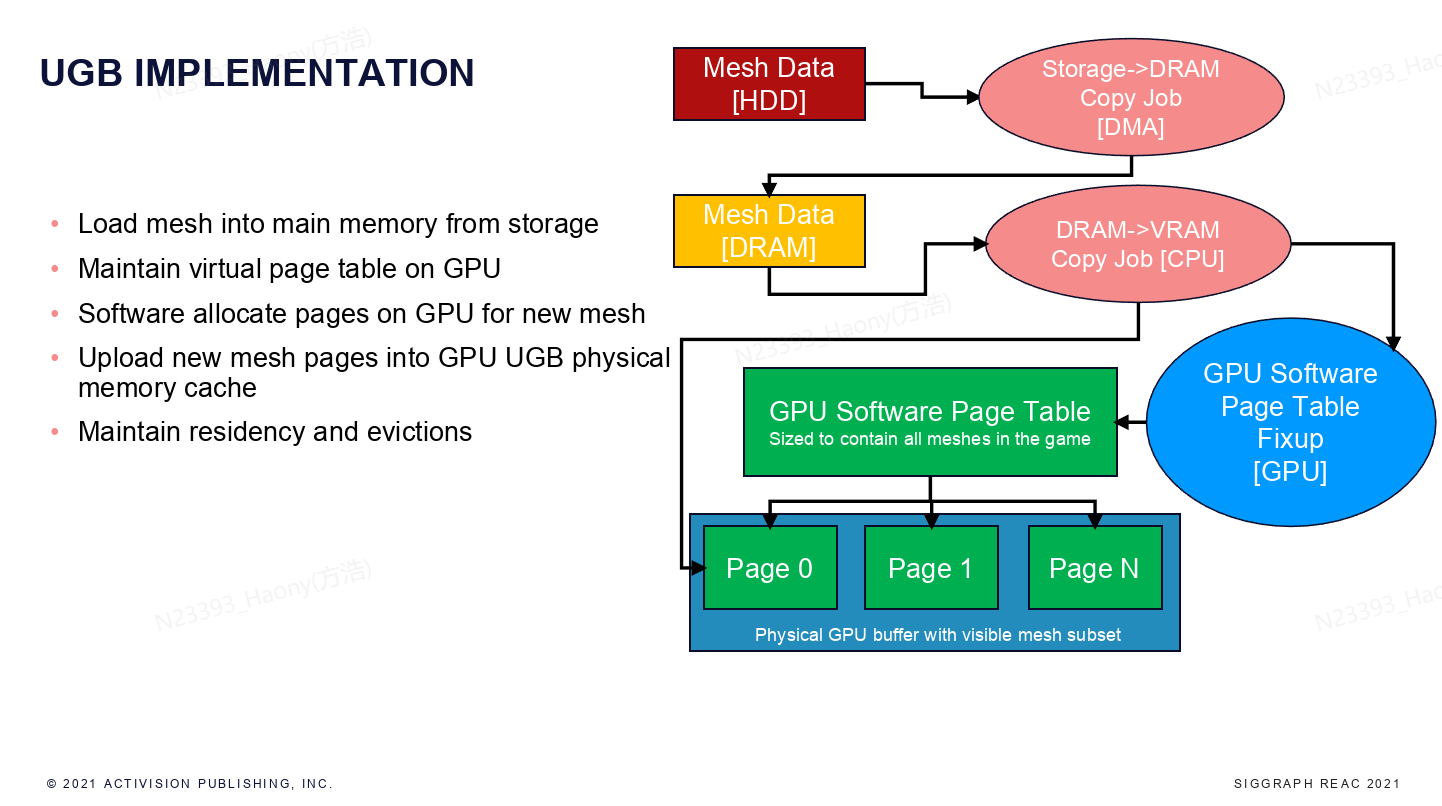
这张图显示了UGB的实现方式,首先Mesh数据会保存在硬盘中,需要加载的网格数据从硬盘中通过DMA直接传输到DRAM中。GPU中采用virtual page来管理内存,并且维护一个Software Page Table,CPU端负责需要更新的数据拷贝到GPU的page中来完成更新操作。
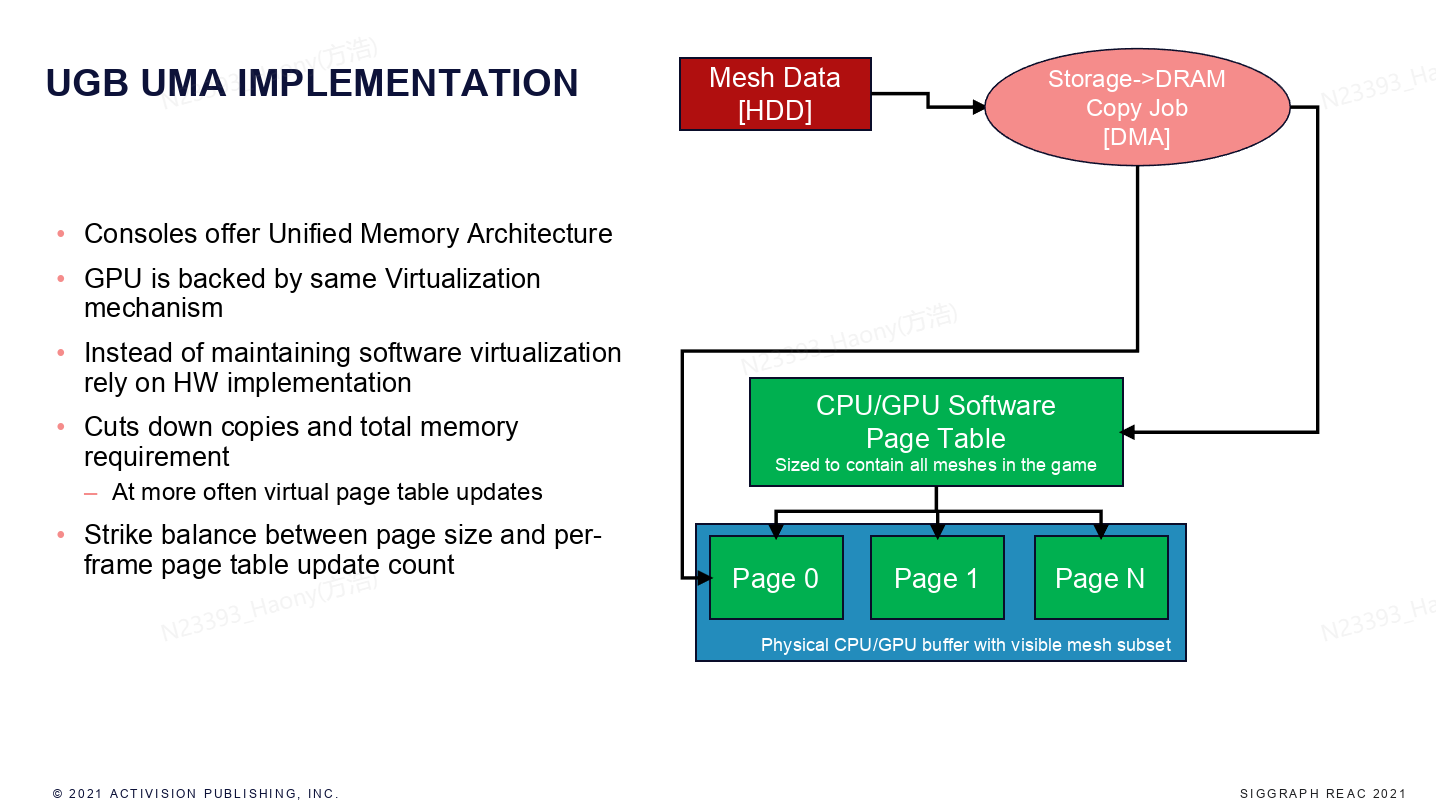
而对于主机等使用UMA统一内存架构的设备上,可以跳过DRAM的加载流程,直接通过DMA将数据从硬盘加载到CPU/GPU buffer上。

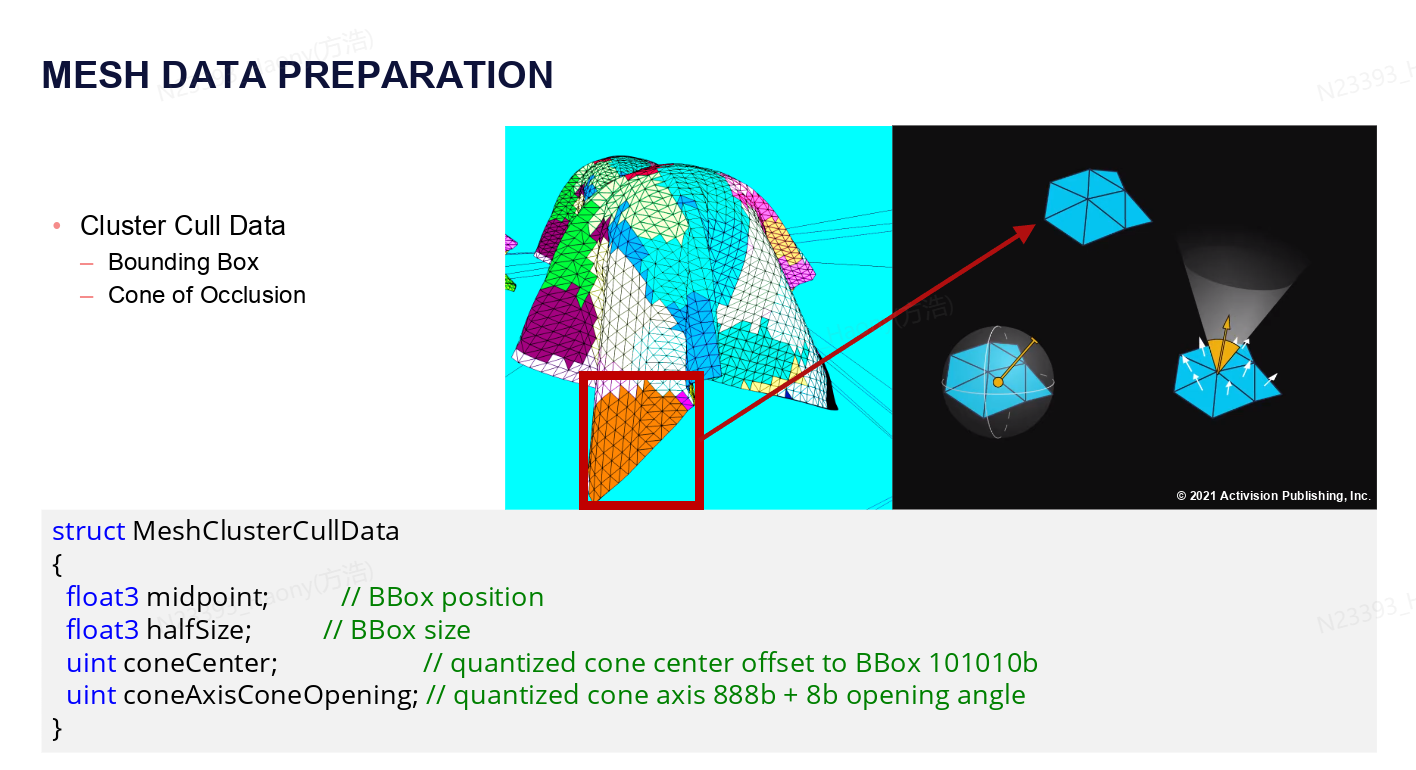
同样,这里需要将原始的网格切分为一个个cluster,每个cluster是一个64 triangle strip,具体的划分会考虑index range, position locality和normal locality等因素,同时还会生成culling需要的数据,包括bounding box和normal cone等。

每个cluster可以进行数据压缩,通过cluster head来记录压缩的信息。如上图所示是index数据的压缩,计算出所有所有index的最小值,然后计算最大值相对于最小值的delta,就可以算出delta的index bits,每个原始的index数据就可以转换为delta index来表示,还原的过程就是将delta index添加上min value即可。同样可以使用相同的方式来编码position。

整个GPU的process pipeline是基于workdgroup为基本执行单元,每个workgroup包括64个item,跟Compute Shader里的thread group一样,每个thread group包含64个thread,可以并行处理 64 个任务。然后任务处理的目标按照层级来进行,依次为Batches -> Models -> Clusters -> Triangles。

这里使用64bit的bitmask来表示每个culling阶段的中间结果。使用bitmask的好处就是可以方便的统计每个view的culling result,并得到这些结果的交集。而且使用bitmask还可以有效的节省内存带宽,真正的source index可以进行高度的压缩表示。
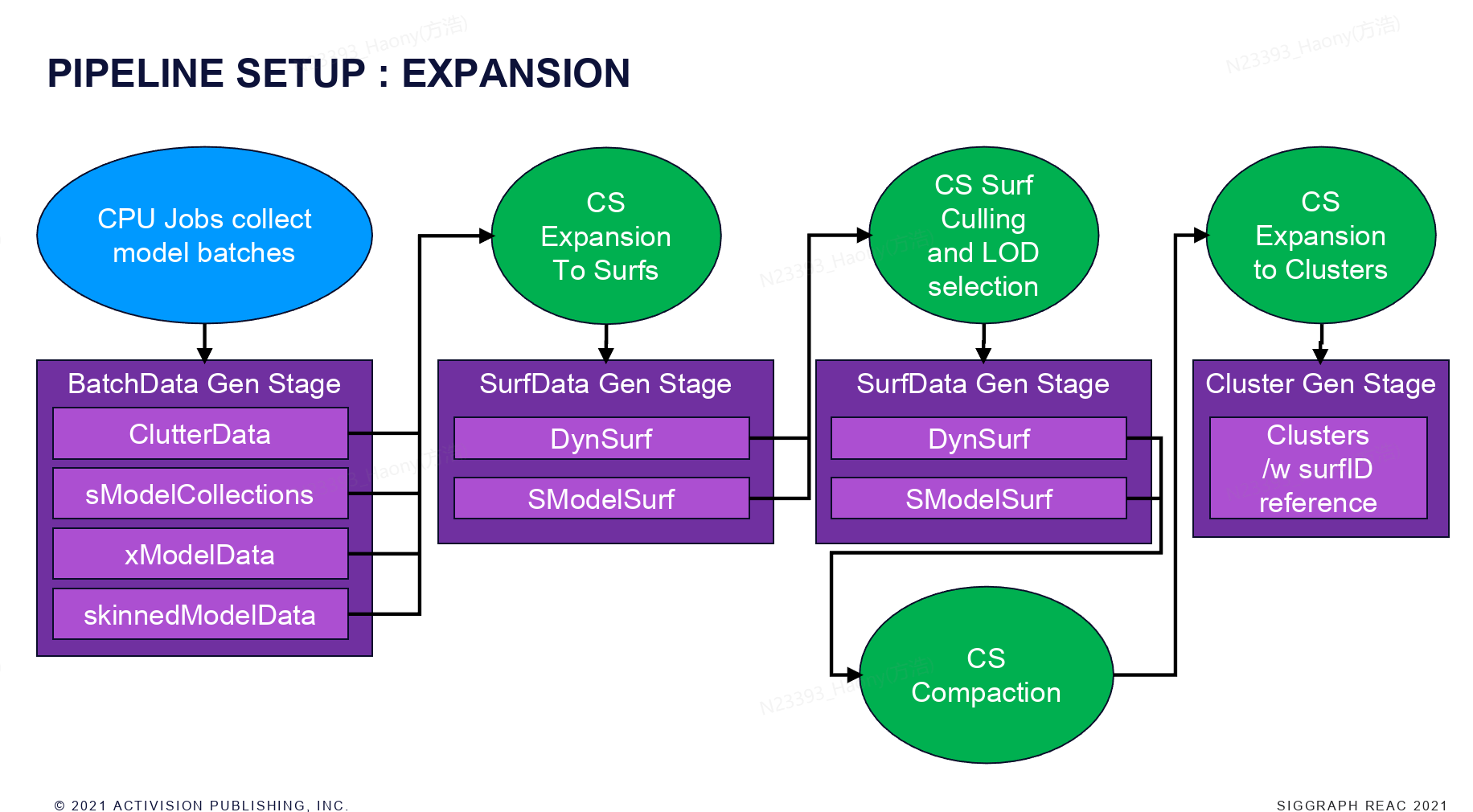
上图是expansion的流程,从CPU端开始,收集场景中的model batches, 其中包括了很多的model类型,然后通过CS将Batch expand成为一系列的动态和静态的surfs,然后进行surf级别的culling和lod选择,culling完成之后,通过CS compaction将可见的surf compact到一起,然后再将surf expand成为cluster,cluster里会记录对应的surf信息。
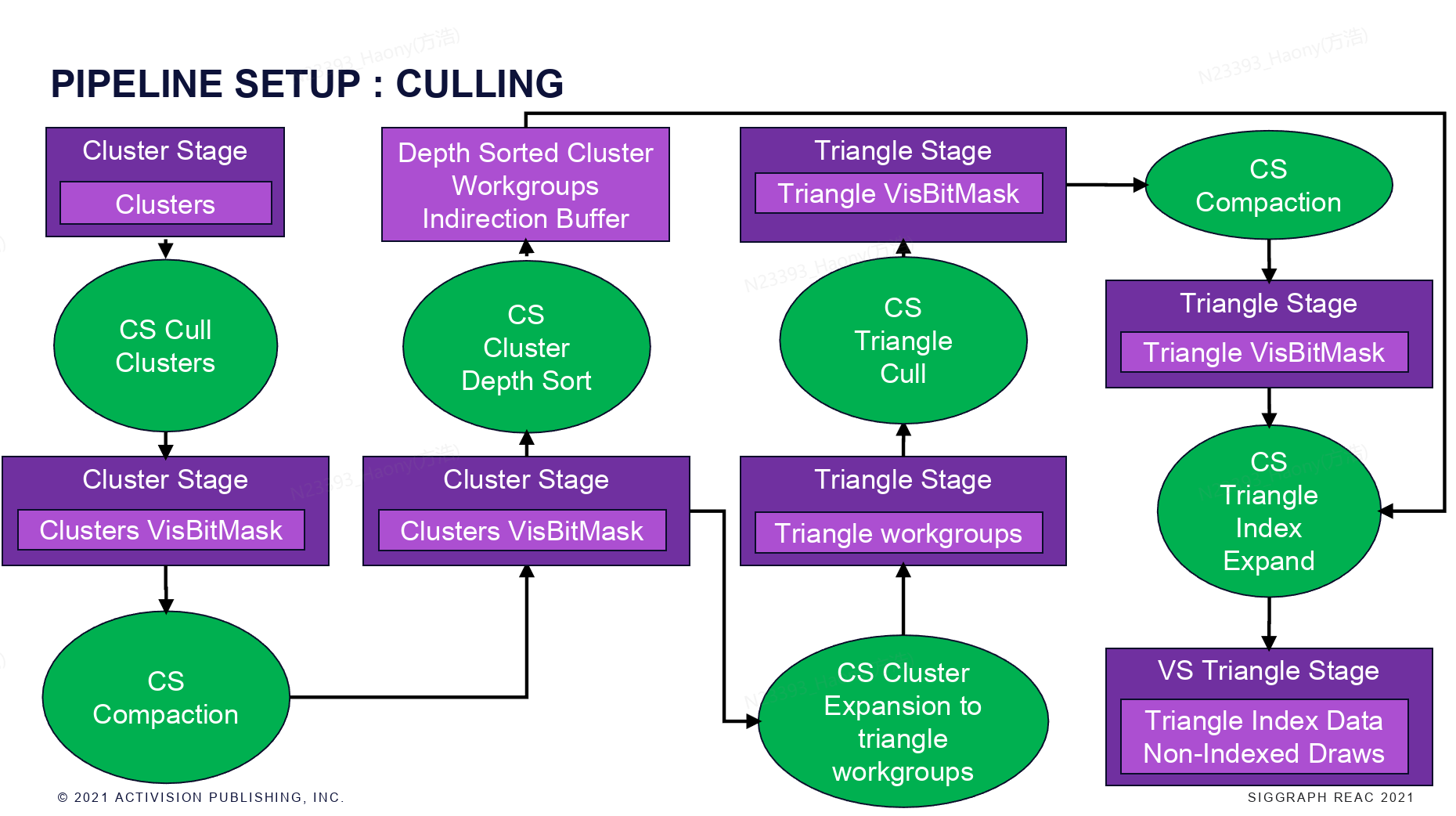
接下来就是cluster和triangle级别的culling。从上图可以清晰的看到整个流程:首先进行cluster级别的culling并compact,获取到cluster的visBitMask,这里需要对Cluster进行深度排序,是为了后续的不透明的绘制可以从前往后进行绘制。可见的cluster还会进行triangle级别的culling,并进行compact,最终得到所有可见的trianglex信息。

针对cluster culling,主要采用了以下的几种culling method:
视锥体裁剪检测:判断三角形簇的所有三角形是否最终落在视锥体内;
退化检测:检测三角形簇是否因坐标变换出现形态畸变(成为退化图元);
采样点缺失检测:判断三角形簇是否存在实际可渲染的可能性;
圆锥背面剔除检测:检测三角形簇的所有三角形是否均为背向视角(可全部剔除)。
另外还支持可选的occlusion culling阶段,针对pre-pass,使用CPU生成的场景深度缓冲区进行检测,针对半透明物体,使用pre-pass的层次化深度缓冲来进行检测。两种方式均采用包围盒进行检测。
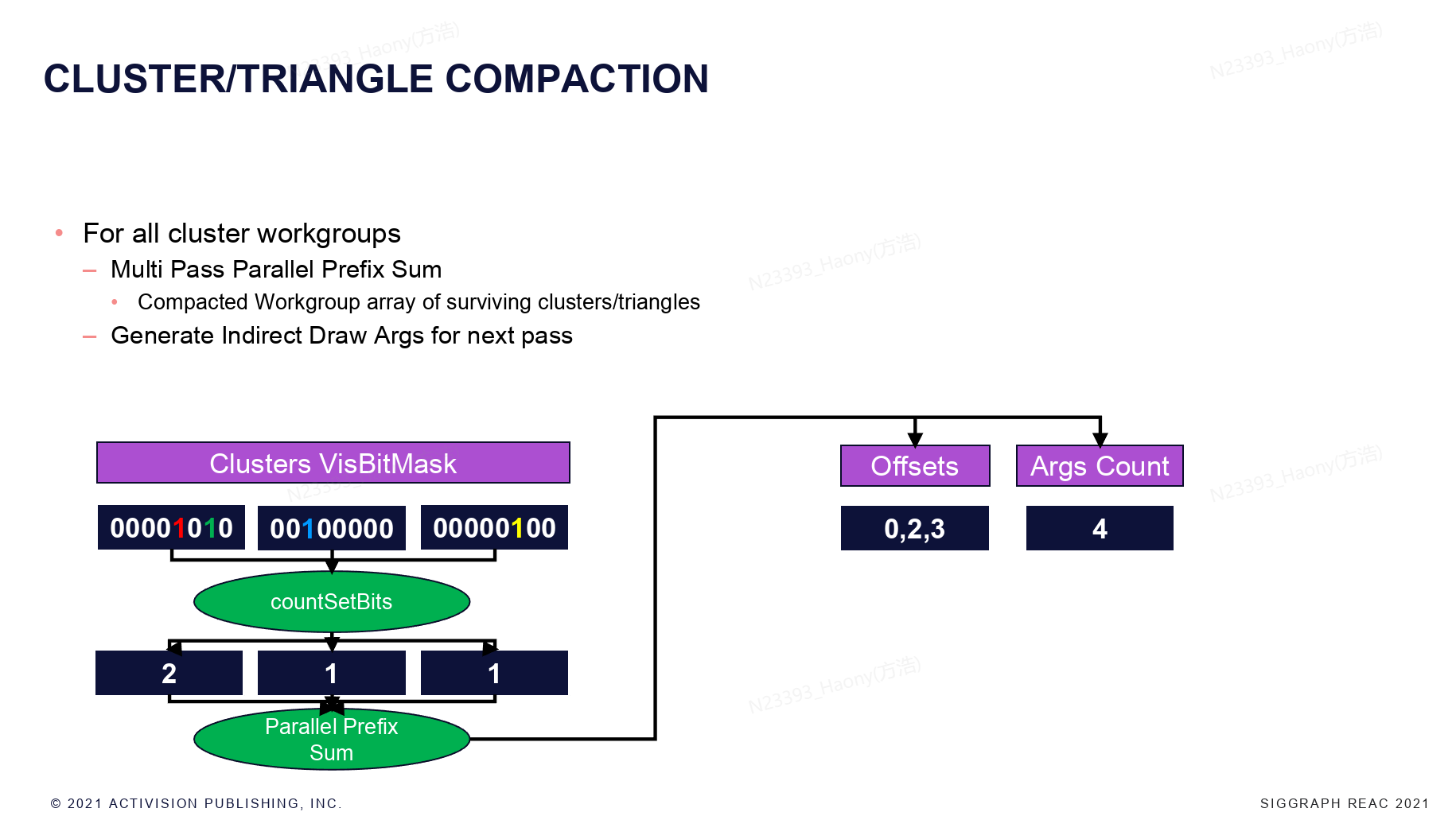
对于所有的cluster的work group,首先每个group统计visBitMask中的bit数量(可见的cluster数量),然后进行并行的prefix sum,可以获取到每个cluster的offset,并且得到所有的可见的cluster的数量。
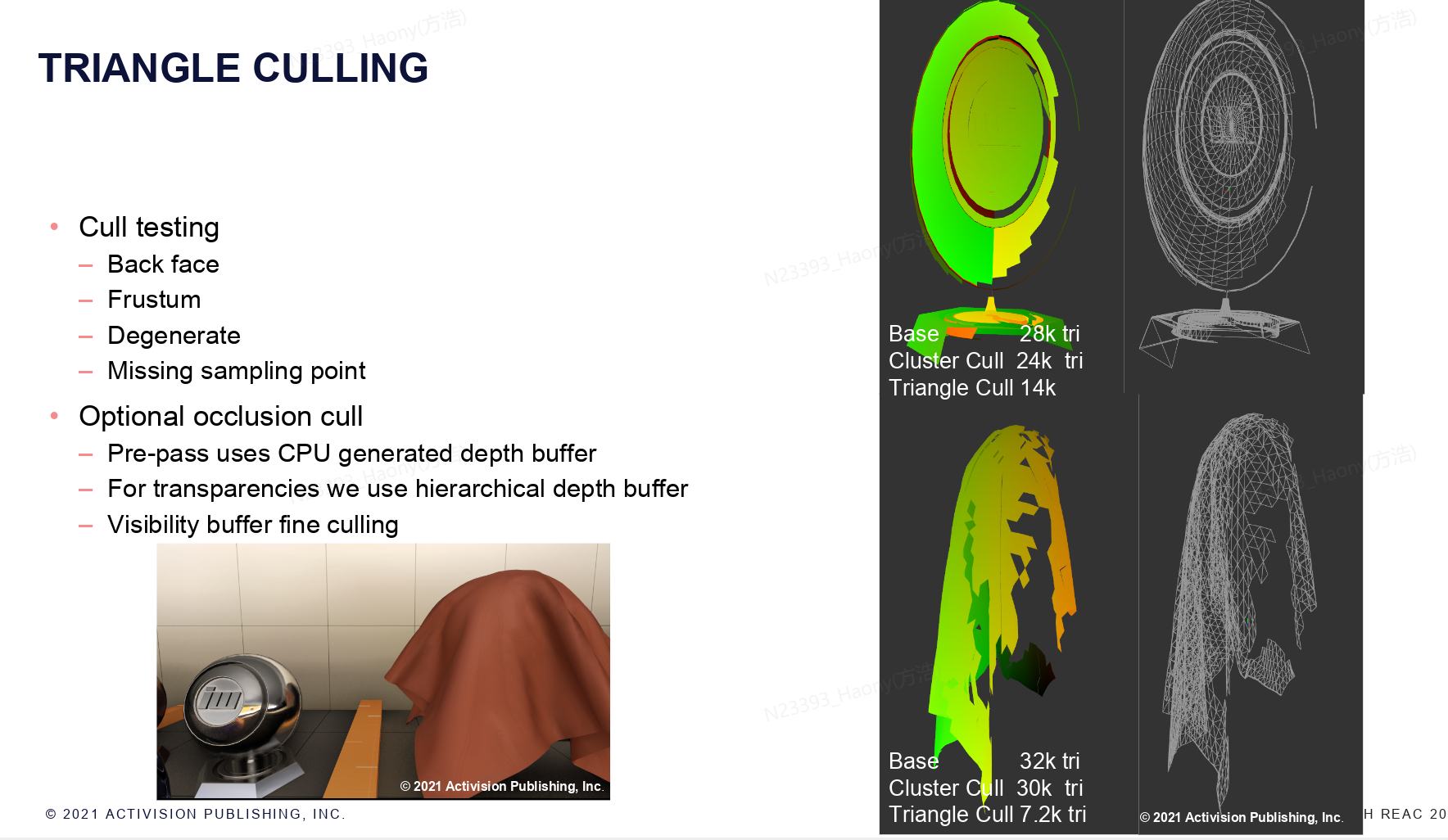
triangle的culling和cluster的culling方式差不多,occlusion culling使用和cluster culling相同的数据,右侧显示了经过cluster和triangle culling之后,剩余的三角形数量,可以看到triangle culling的效果会好很多。
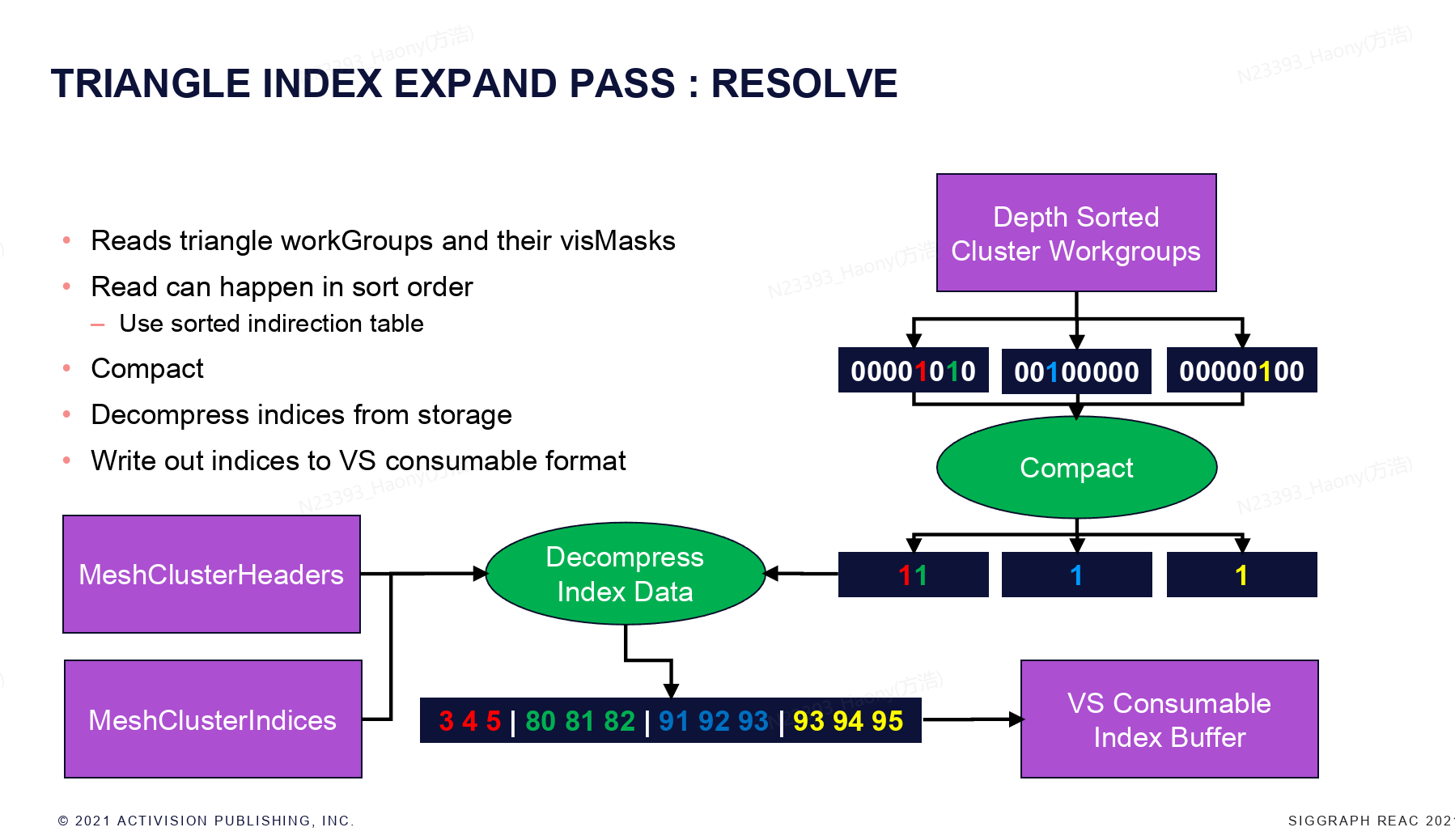
跟cluster的流程类似,获取每个cluster的triangle visBitMask之后,将可见的triangle信息统计出来,因为这里存储的是triangle的index,而实际需要绘制的是vertex的index,因此这里需要Decompress index data,将其compact到最终VS需要的index buffer上。
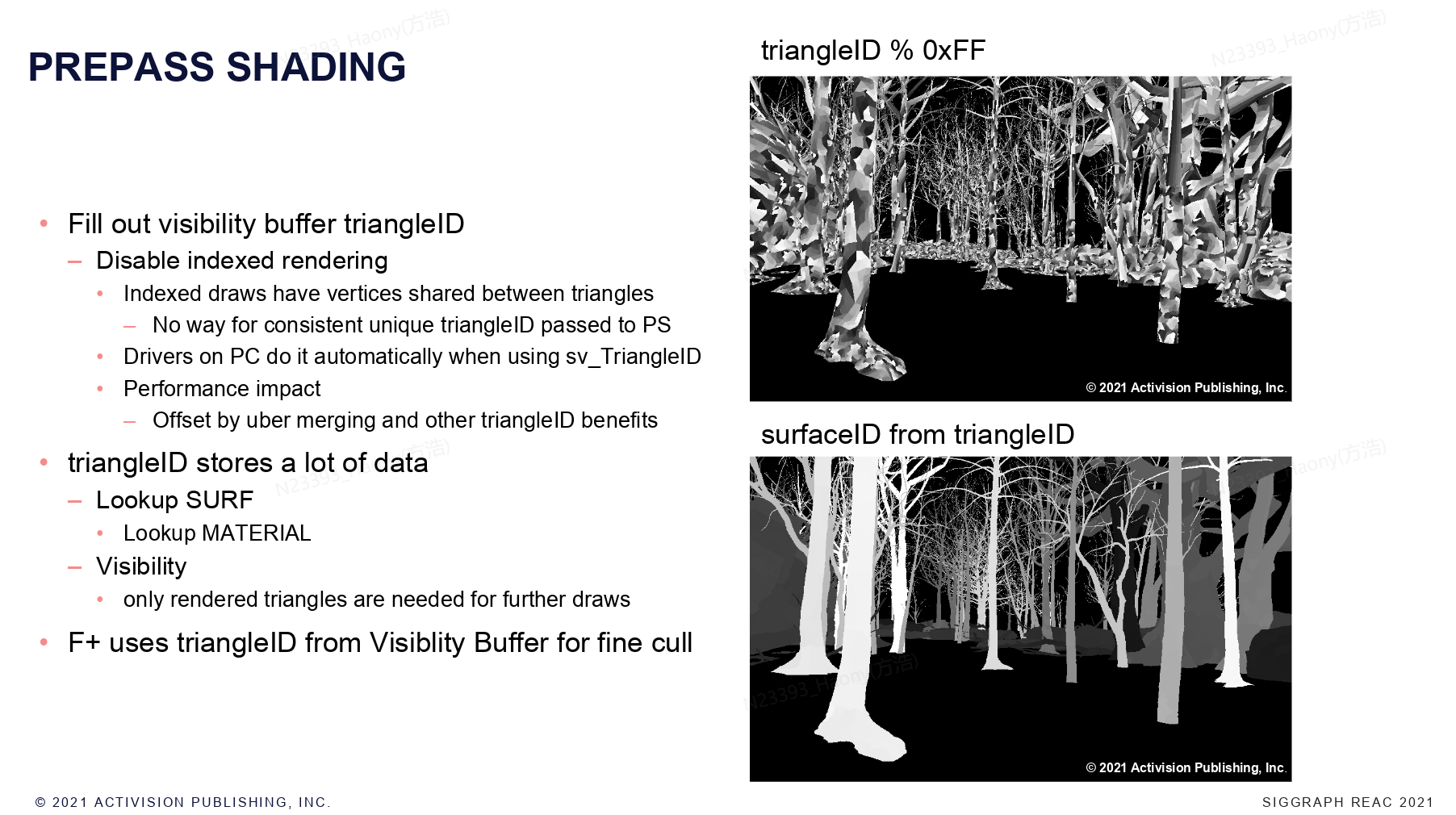
在pre-pass阶段,一个重要的任务是将triangleID写入到VisBuffer中,在index drawcall中,多个三角形会共享顶点,无法在PS中获取一致且唯一的triangleId,所以这里针对于使用VisBuffer的地方禁用了indexing。有了triangleId,实际上就可以做很多的事情,比如查找surf,material等,以及逐像素的culling。

上图是F+ Culling的流程,根据pre-pass获取的Hierarchy Depth Buffer和triangeID Buffer,进行triangle culling, 然后进行compact,最后culling。

这个是所有阶段的剔除率和可见的三角形数量。
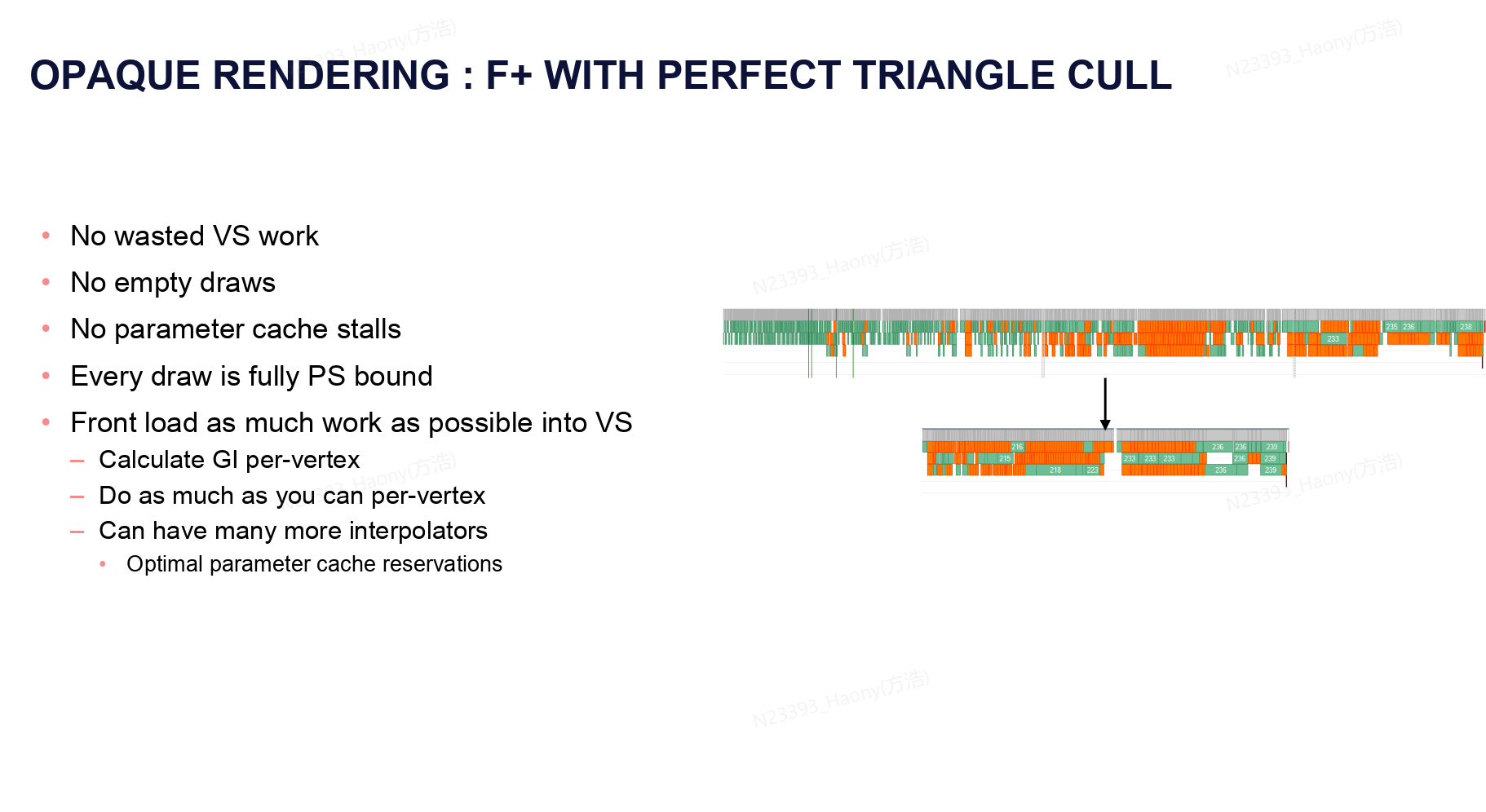
像素级别精准的三角形剔除可以带来诸多的优势:
VS没有任何无效的计算开销。
不存在无效的空的drawcall(指没有绘制任何三角形)
不会产生 parameter cache stlls,也就是减少频繁切换绘制参数带来的性能消耗
每次drawcall的性能瓶颈都在PS阶段。
这种设计架构也会尝试将更多的计算任务前置到顶点着色器进行。具体的情况需要根据引擎的实际情况决定。
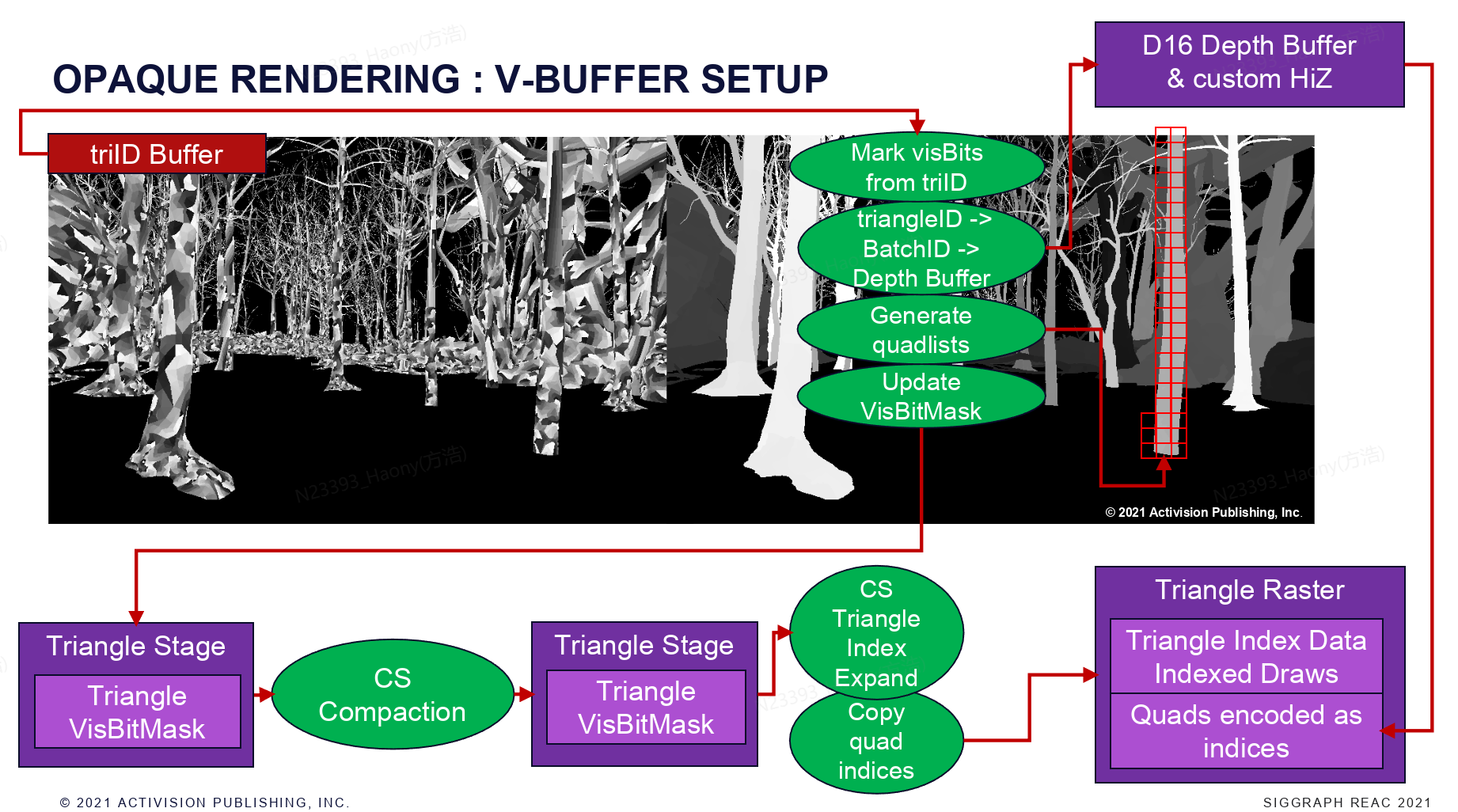
最后就是V+的pipeline,不过这个方案他们还只是实验阶段,并没有在实践中进行使用,关于visiblity buffer的技术,后续会开专门的一个文章来介绍下。
本文围绕动视暴雪SIGGRAPH 2021分享的几何渲染管线架构展开。开放世界场景三角形数量达800多万(较原场景增10倍),需高效处理。对比Forward+(F+)、Deferred、Visibility+(V+)三种管线:大尺寸三角形场景V+性能接近F+,超高面数网格场景V+持平Deferred且材质复杂时更优。最终采用F+与V+混合管线,普通密度网格等用F+,高密度网格等用V+。还构建BATCH - SURF - CLUSTER层级,借助Unified Geometry Buffers(UGB)统一管理几何数据,将网格切分为64三角形strip的cluster,通过多阶段剔除(视锥体、退化等检测)及并行处理,实现高效渲染。
参考文献
https://research.activision.com/publications/2021/09/geometry-rendering-pipeline-architecture
