
GPU Driven Rendering (一)
GPU Driven Rendering(GPU驱动渲染)是一种现代实时的渲染架构,其核心思想是将渲染流程的控制权从CPU转移到GPU,把原本在CPU上执行的关键任务(如几何裁剪,视锥剔除,遮挡剔除,DrawCall的生成)转移到GPU端,让GPU使用Compute Shader或Mesh Shader来完成,让GPU自主决定渲染哪些内容以及如何进行渲染,从而大幅减少CPU与GPU之间的数据传输和交互开销,充分发挥现代GPU的并行计算能力。
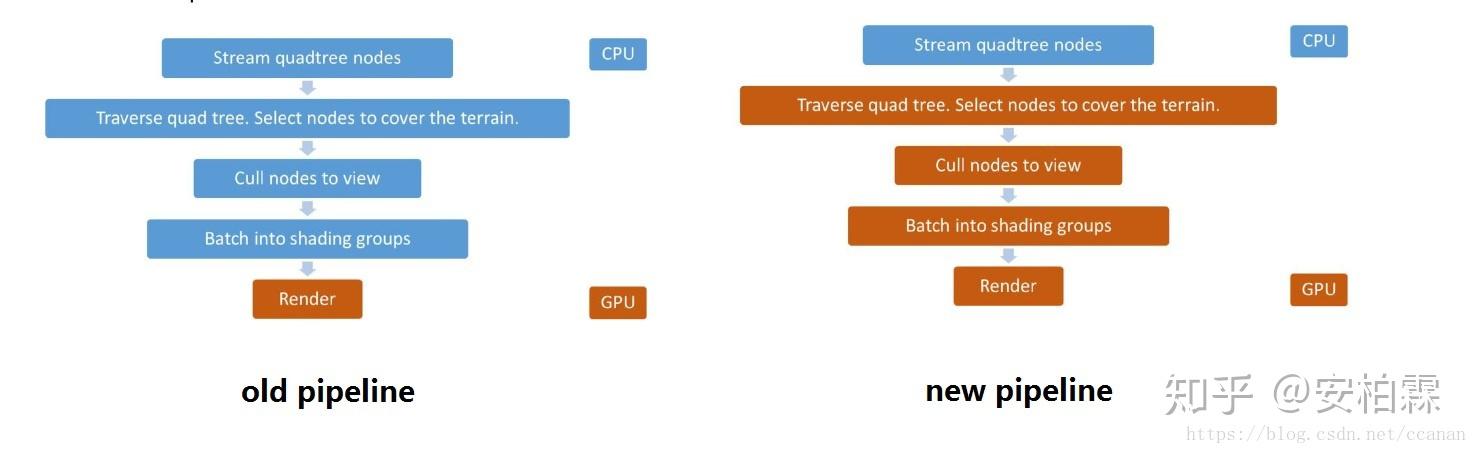
【SIGGRAPH 2015】GPU-Driven Rendering Pipelines

上图为《刺客信条大革命》游戏中育碧提出的GPU Driven Rendering Pipeline,其中蓝色部分为CPU侧的工作内容,而红色部分为GPU侧的工作内容。
Coarse Frustum Culling

这个步骤主要是CPU端进行Instance的Culling,场景会被组织成为四叉树,八叉树或者BVH,然后可以利用这些加速结构对场景中的Instance进行快速的剔除,同时在CPU端对每个Instance的数据根据LOD,Material等信息建立Batch,用于后续发起DrawCall。
越早做剔除性能会越好。大革命中在CPU端做剔除,可以节省从CPU到GPU的数据上传带宽,但是缺点是会浪费CPU的性能,这部分Instance Culling的工作实际也可以放到GPU端来进行。
Instance Culling
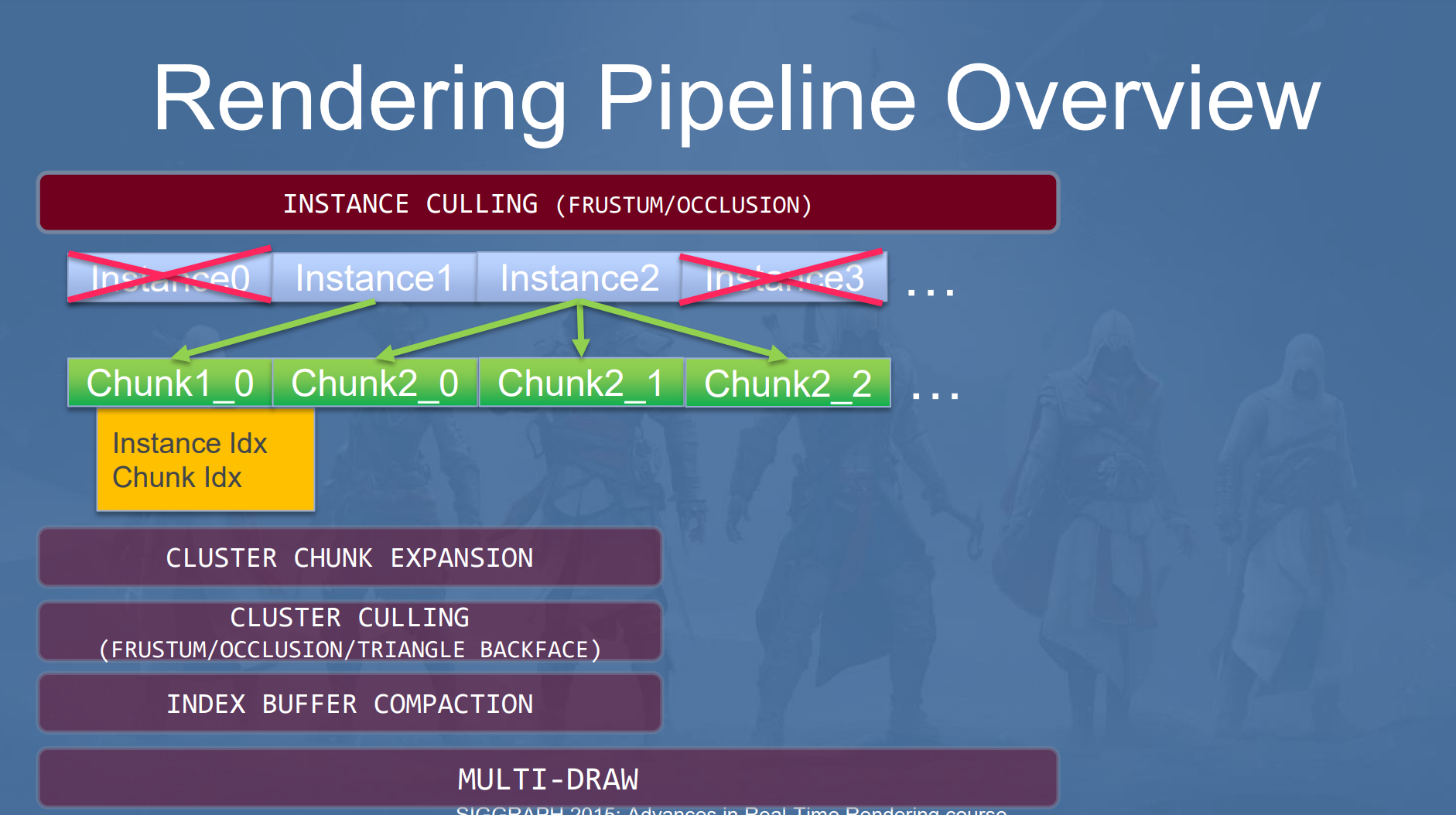
在GPU侧,首先会进行Instance Culling, 包括Frstum/Occlusion Culling,这里与CPU侧的culling不同之处在于:CPU侧只根据加速结构进行粗粒度的Culling,是Batch级别的,而且只有Frustum的剔除,GPU侧则是逐个Instance的精细剔除。

通过测试的Instance会被拆分为Cluster,每个Cluster为一个64 Vertex strip,之所以拆分为Cluster,是为了能够更加精细的进行剔除,尽可能减少需要渲染的三角形数量。
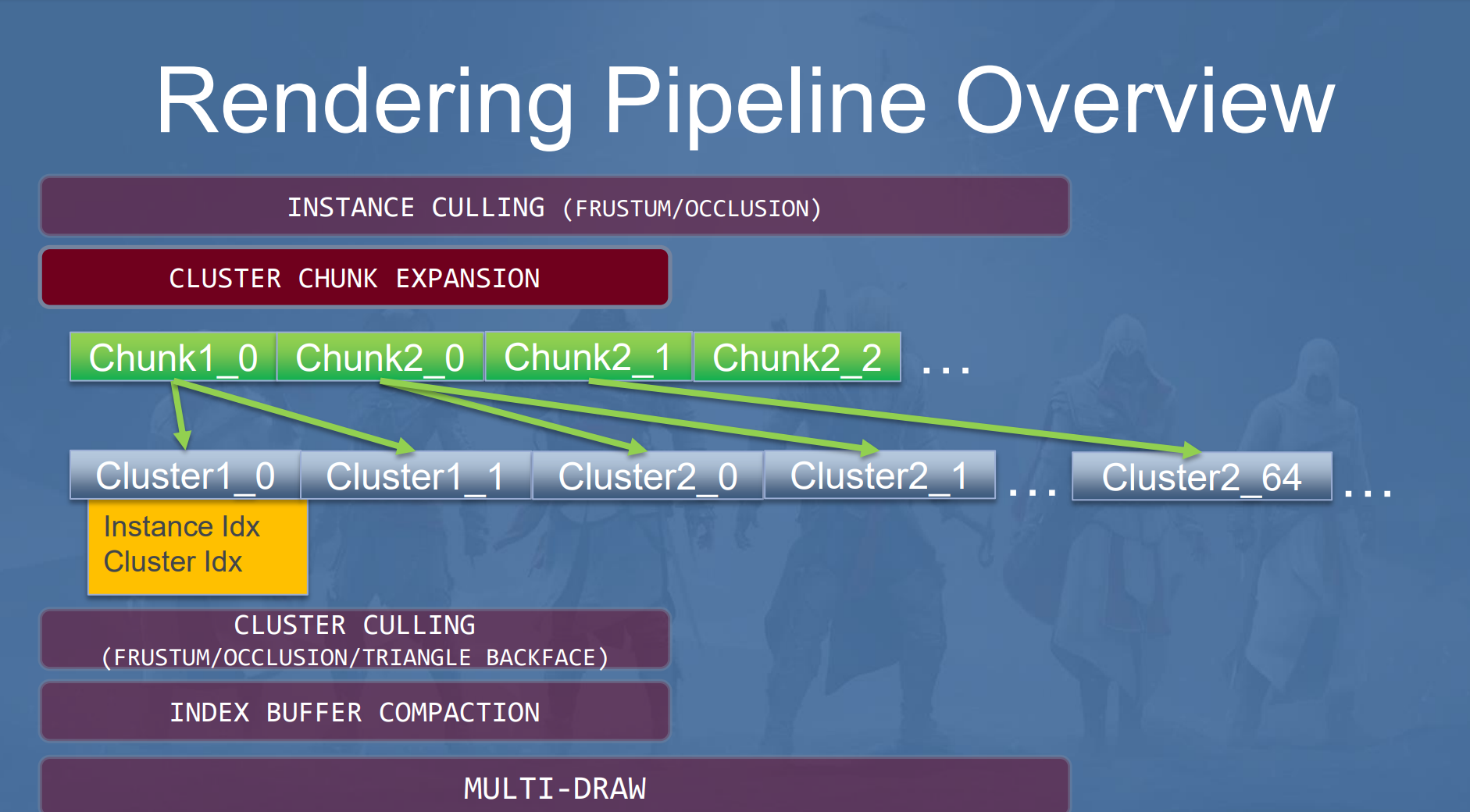
由于每个模型原始的三角网格划分的Cluster数量各不相同,差别可能比较,会造成warp的浪费。因此这里首先将每个Instance生成Cluster Chunk,然后再将chunk拆分为Cluster。
Cluster Culling
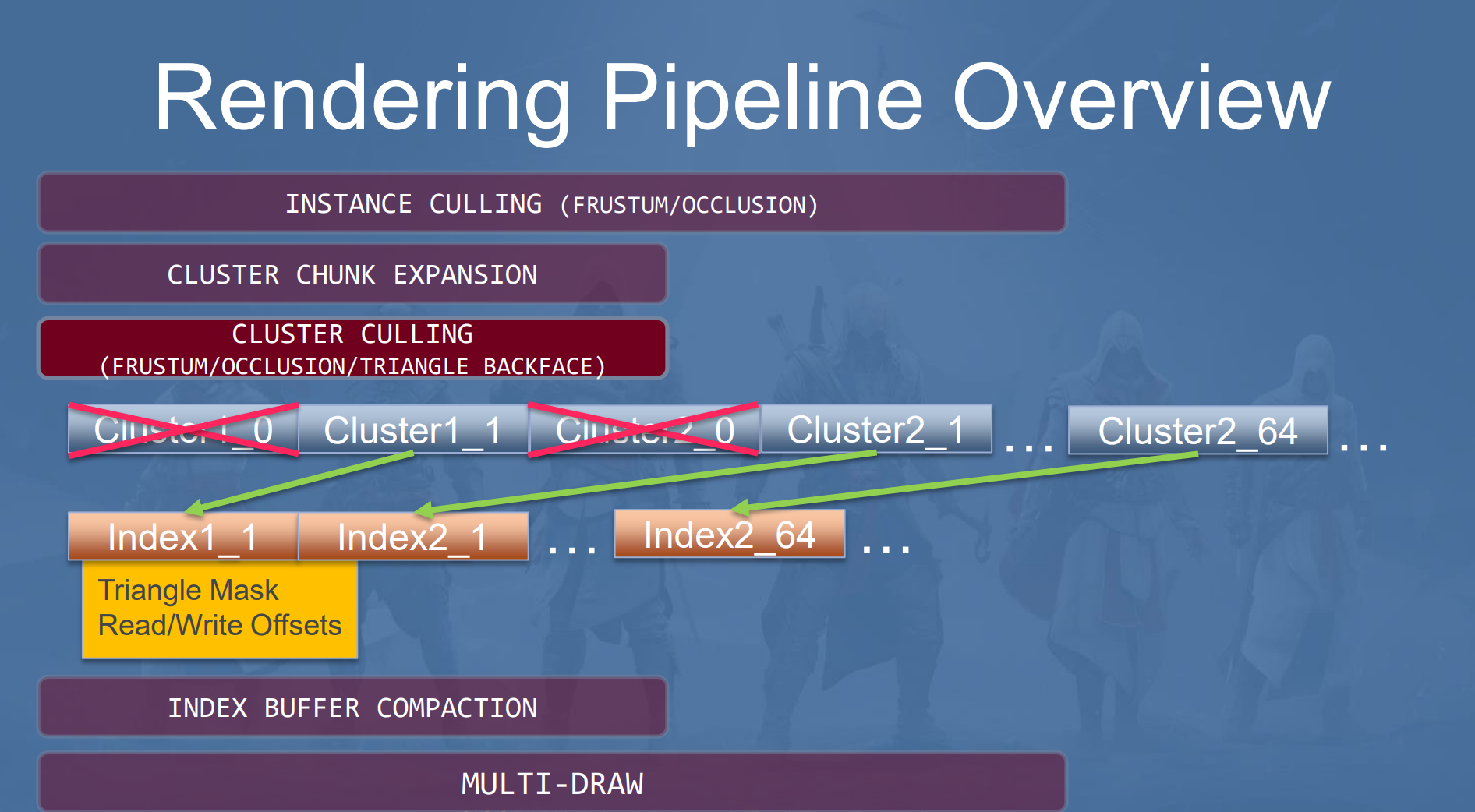
原始的模型被拆分为一个个的Cluster,然后就是针对这些Cluster进行更加精细的Cluster Culling,包括Frustum/Occlusion/Traignel Backface Culling。其中Frustum和Occlusion Culling跟Instance的Culling方式一样,Triangle Backface Culling则是通过离线烘焙进行的。

对每个三角形会烘焙一个Cubemap六个面的可见性,需要存储的大小为6bit,再运行时的时候,给定相机的位置,则可以通过查询cubemap获取到一个64bit的mask来表示cluster里每个三角形的可见性。
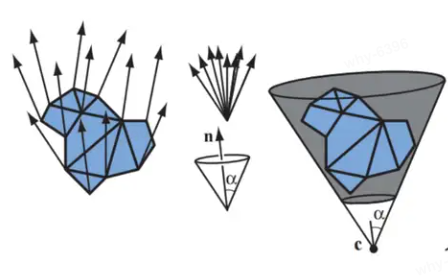
另一种更加方便的backface culling方式是通过normal cone来进行,如上图所示,通过cluster内所有三角形的normal计算出一个normal cone,然后再运行时,判断该normal cone的可见性来判断该cluster的可见性。不过这里每个cluster的所有三角形要么全部可见,要么全部不可见,所以本质上还是针对Cluster级别的可见性判断。
在Fine-grained backface culling的测试结果,可以看到实际中Normal Cone Backface culling的剔除率实际并不高,主要有几点原因:第一是如何cluster中有一个三角形可见,那么就表示该cluster全部可见,在实际的cluster划分的结果中,cluster内的三角形的法线朝向并没有那么的集中,所以剔除效果很差。第二个就是GPU在渲染过程中本身就会自带三角形背面剔除,因此实际剔除的性能提升很有限,再加上剔除pass本身的消耗,有时候甚至会是负优化。
IndexBuffer Compaction
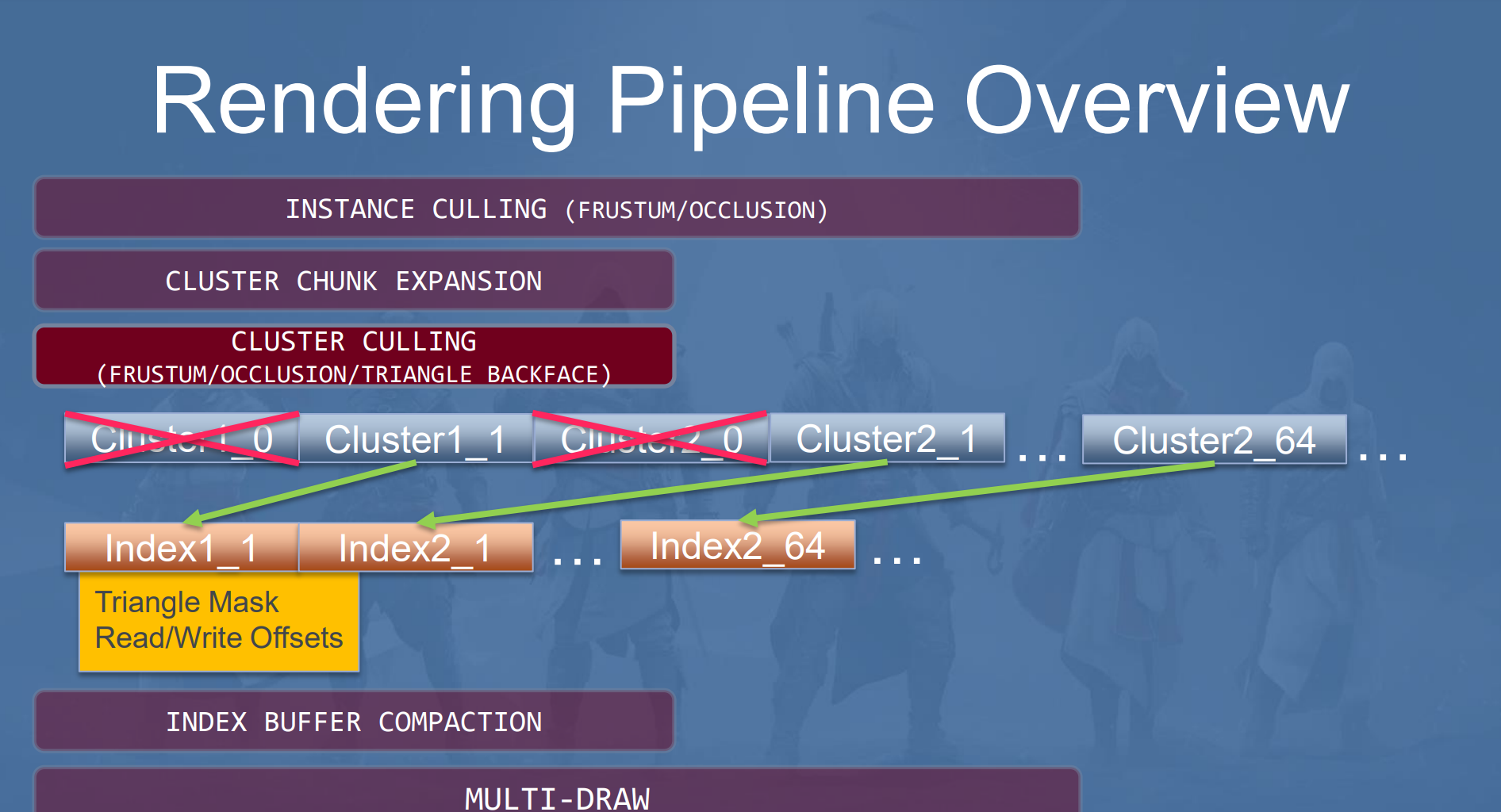
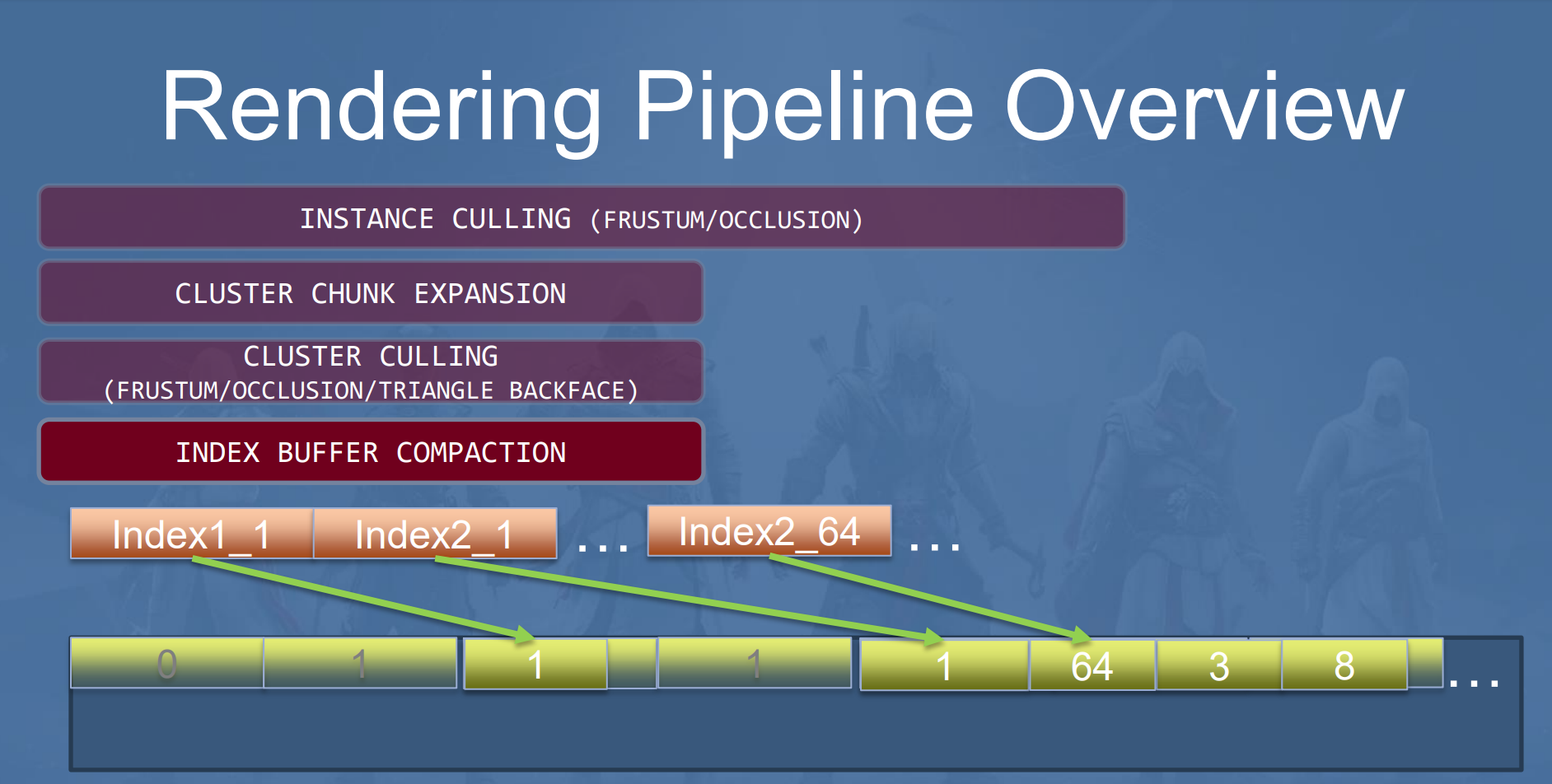
Cluster Culling完成之后,剩下的Cluster就都是可见的需要绘制的Cluster了,每个Cluster对应原始的IndexBuffer中的一部分,通过InstanceId和ClusterId来进行定位。然后通过IndexCompactionPass将每个Instance可见的index Compact到一个大的CompactedIndexBuffer上,注意,这个buffer的大小是预留的原始的每个Instance的所有IndexBuffer的大小。
MultiDraw Indirect
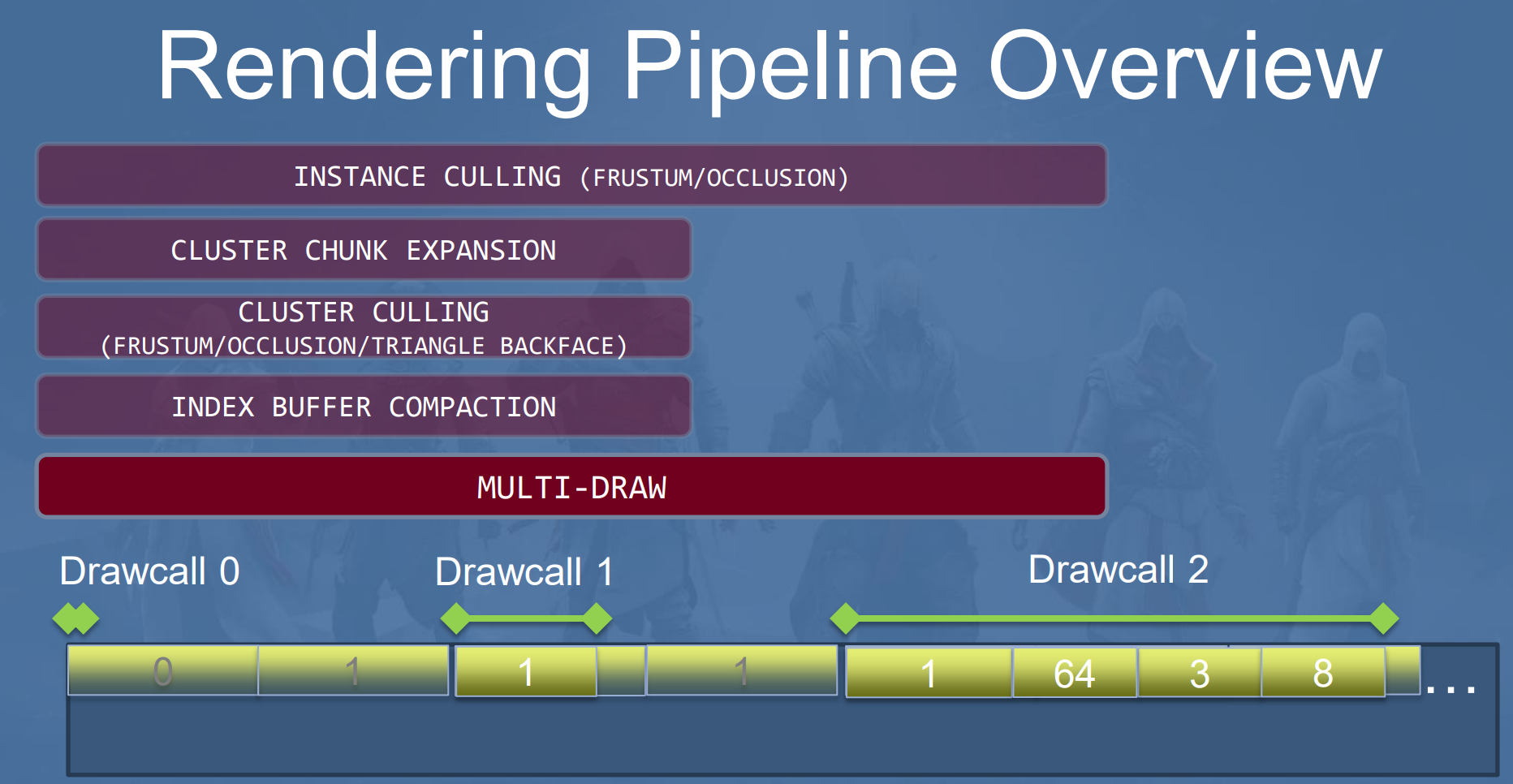
Culling完成,数据准备好之后,最后就是发起DrawCall了,这里使用的IndirectDraw,也就是由GPU端提供DrawCall所需要的参数。MultiDrawIndirect 是 OpenGL/Vulkan/DirectX 中实现 “GPU 生成绘制命令” 的核心接口,其参数本质是一个结构化的缓冲区数据(而非直接传入的零散参数),不同图形 API 的参数结构略有差异,但核心字段完全一致。
1 | // OpenGL 中 MultiDrawIndirect 的基础参数结构体 |
对于被剔除的Instance数据,对应的IndirectArgs里的instanceCount数据可以设置为0,如果instance通过了剔除阶段,但是其cluster都被剔除了,那么indexCount就被设置为0,对于驱动而言,上述两种情况,这个DrawCall就会被优化掉。
总结而言,刺客信条大革命中,将传统的基于逐Instance的剔除,细化到逐Cluster甚至是逐个三角形的剔除,实现了更高的剔除效率,减少了Overdraw。同时将之前在CPU端的工作,比如剔除,数据传输,DrawCall的发起等操作移动到GPU端进行,有效的减少了CPU的负载,提高了GPU利用率。这也是GPU Driven最核心的技术思想。
参考资料
