
深入理解GPU(一) 渲染管线
使用一个东西,却不明白它的道理,并不高明.
做图形学最重要的就是跟GPU打交道,利用GPU来实现各种效果。但是之前一直只停留在比较上层的使用上,对于GPU的底层和硬件架构知之甚少。借用侯捷老师的一句话“使用一个东西,却不明白它的道理,并不高明”。于是便花了些时间深入学习了GPU的相关知识,做些记录。
腾讯技术工程的官方号上有一篇详细介绍GPU的文章:《GPU 渲染管线和硬件架构浅谈》,总结的非常全面,反复看了好多遍,也是本篇文章的主要参考资料。知乎平台上讲解NVIDIA GPU架构的系列文章非常详细的介绍了各代架构的GPU及其硬件架构,非常值得一读。
RTR4开篇第一二章的内容就是介绍的GPU硬件架构和渲染管线,这里我们也按照这个顺序:
- 第一篇将主要介绍图形学中的GPU渲染管线,包括桌面端和移动端;
- 第二章主要介绍GPU的硬件架构;
- 第三章主要介绍GPU编程和优化方法相关。
GPU渲染管线
所谓的GPU渲染管线,就是有一堆的模型数据(点,线,三角形等),经过GPU端的一系列的流水线处理,最终得到屏幕上的二维图像的流程。跟工业生产的流水线一样,GPU的管线各个部分也是并行处理的。RTR4中将渲染管线分成了四个部分:
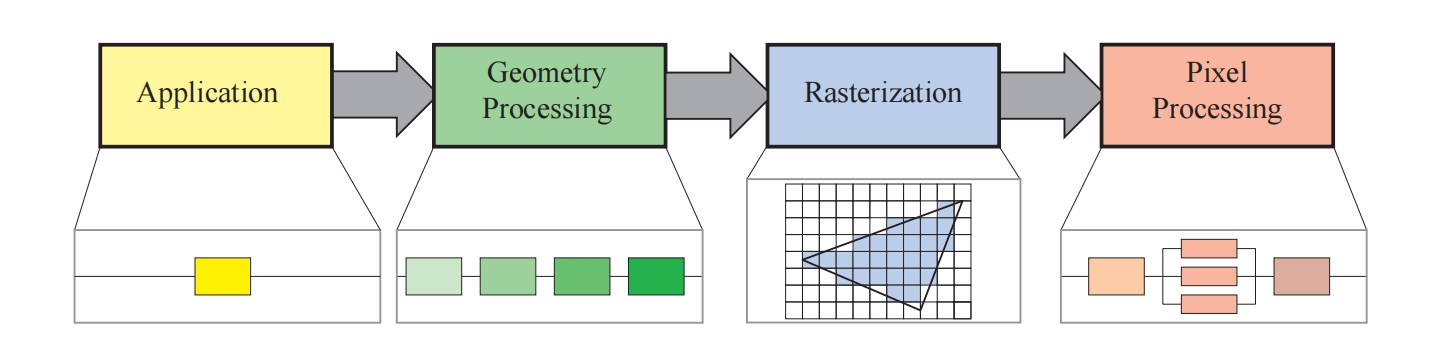
应用阶段 (application):应用阶段顾名思义就是通过应用驱动的,CPU端拥有多个核心,可以执行应用阶段的多种人物,包括物理,动画,碰撞监测,空间加速等等。同时应用阶段的最后会指定GPU端渲染所需要的数据,包括点,线,三角形等图元(render primitive),贴图等,同时告诉GPU端该按照怎样的顺序以及方式来渲染。
几何处理阶段 (geometry): GPU部分的最开始会逐顶点和三角形的进行几何处理。如果将几何处理阶段再进行细分的话,主要包括以下四个阶段:顶点着色(Vertex Shading),投影(Projection),裁剪(Clipping),屏幕映射(Screen Mapping)。
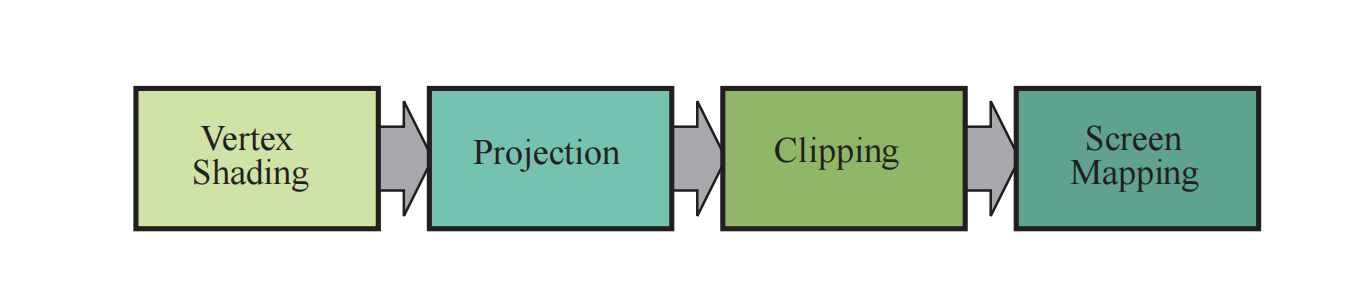
顶点着色主要有两个任务:一是计算顶点位置,另一个是计算作为顶点数据输出的任何参数,包括法线,纹理坐标等。其中计算顶点位置主要包含顶点的几个空间转换,包括:模型空间(model space),通过Model Transform转换到世界空间(world space),然后通过View Transform转换到相机空间(camera space或view space), Model Transform和View Transform都是通过4x4的matrix实现,分别叫做 Model Matrix 和 View Matrix。
几何处理的第二个部分是投影。投影的目的是为了将物体空间中的三维坐标映射为平面的二维坐标。投影分为两种:透视投影(Perspective)和正交投影(Orthographic)。正交投影的可视空间是一个标准立方体,这样的投影由一个位移变换和一个缩放变换组成。透视投影则模仿的人眼的透视效应,透视投影的可视空间(也称作视锥体)是一个具有矩形底面的截断金字塔,投影完成之后的视锥体也会被变换为一个标准立方体。正交和透视投影都可以用一个4x4的矩阵来表示,这个矩阵也叫做Projection Matrix。投影过后的坐标系叫做裁剪坐标系(Clip Coordinates),记录的坐标叫做齐次坐标(Homogeneous Coordinate).GPU顶点着色器必须输出齐次坐标,以便于下一个功能阶段裁剪可以正确执行。完成顶点处理之后,还有几个可选的阶段可以执行:曲面细分(tessellation),几何着色器(geometry shading)和流式输出(stream out)。
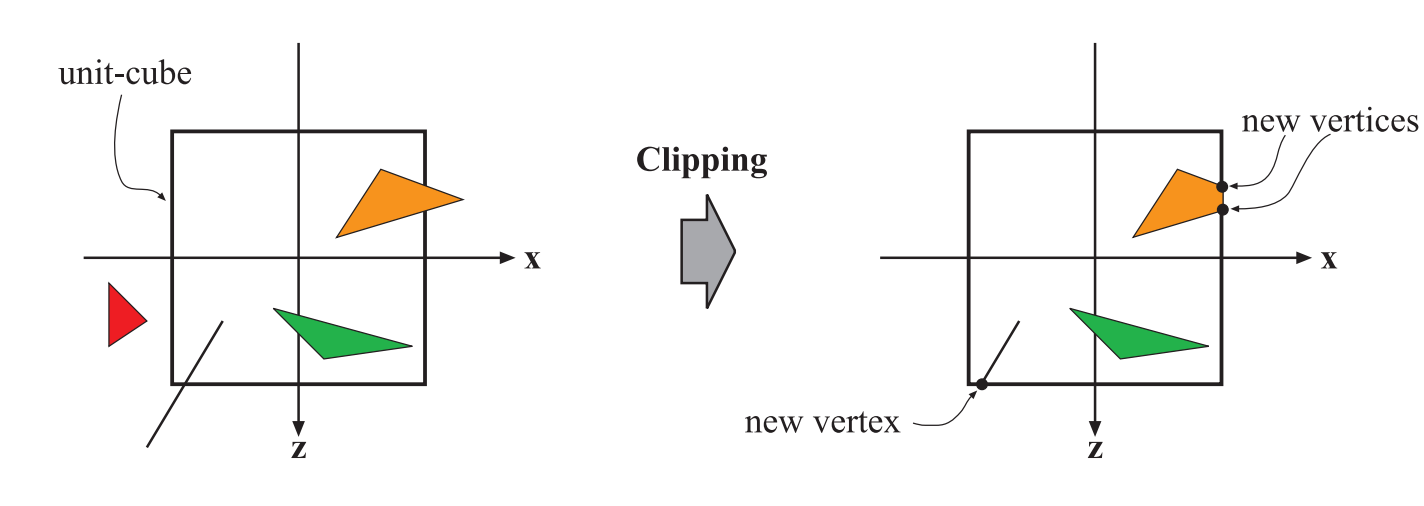
对于完全位于可视空间内部的图元,直接进行处理;对于完全位于可视空间外部的图元,直接剔除;低于部分在外面,部分在内部的图元,需要进行裁剪。图元经过裁剪之后会产生新的顶点。裁剪过后会进行透视除法,将三角形的位置转换到标准设备坐标系NDC(Normalized Device Coordinates)。NDC的范围是(-1,-1,-1)到(1,1,1)。
几何处理的最后阶段是屏幕映射(Screen Mapping)。当图元进入该阶段时还是三维坐标,其中x和y被称作屏幕坐标(Screen Coordinate),屏幕坐标加z坐标一起叫做窗口坐标(Window Coordinate)。假设该场景被渲染到屏幕上一个窗口中,窗口左下角为(x1,y1),窗口右上角为(x2,y2),那么原来的屏幕坐标会被映射到范围在(x1,y1)到(x2,y2)的范围内,z坐标同样也被映射到[z1,z2],OpenGL中[z1 = -1,z2 = 1],DirectX中[z1 = 0,z2 = 1],最后屏幕坐标和映射之后的z一起传送到光栅化阶段。
下面描述下整形数值和浮点数值与像素和纹理坐标之间的对应关系:
给定一个笛卡尔坐标系进行描述的水平像素数组,最左侧像素中心点坐标为0.5,该像素的左边界为0,右边界为1,OpenGL和DX都使用了该规定。转换规则如下:
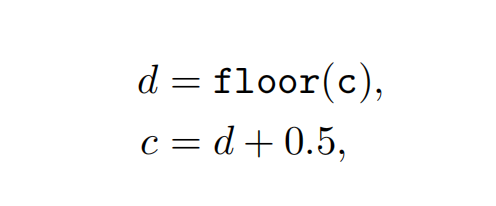
其中d表示像素的位置索引(整型),c表示像素内的连续值(浮点型),也就是实际采样的位置。
所有API都定义像素坐标从左到右依次增大,OpenGL将竖直方向从下到上依次增大,起点在左下角;DirectX将竖直方向从上到下依次增大,起点在左上角。
光栅化阶段 (rasterization):
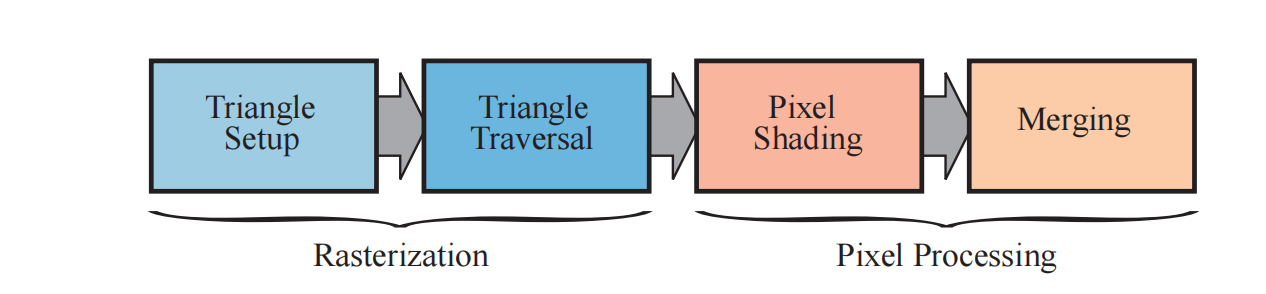
在经过几何处理阶段之后,图元被变换到了屏幕指定的窗口位置,而光栅化阶段则是为了找到该图元需要渲染的像素。光栅化分为两个阶段:三角形设置(Triangle Setup)和 图元装配(Primitive Assembly)。关于光栅化的详细内容可以参考该文章,具体介绍了光栅化算法原理和各种抗锯齿的算法。像素处理阶段 (pixel):
经过了上述的流程之后,我们已经找到了位于图元内部的所有像素,最后阶段就是对这些像素进行着色处理。像素处理阶段主要分为着色和合并两个阶段。- 像素着色:像素着色的输入时经过插值的顶点数据,每个像素单独计算,在GPU中是使用的可编程的GPU核心来执行,称作片元着色器(pixel shader)。在pixel shader进行各种计算,最终输出一个颜色用于下一个子阶段。
- 像素合并:颜色缓冲区(color buffer)是一个矩形阵列,它存储了每个像素中的颜色信息,在像素着色阶段计算得到的颜色值,会被存储在颜色缓冲区中,合并阶段就是将这些片元的颜色进行合并。这个阶段也叫做ROP(Raster Operations Pipeline)。这个阶段并不是可编程的,而是可配置的。如颜色的混合测试,深度测试,模板测试和Alpha测试等。其中深度测试时通过**深度缓冲区(Depth Buffer 或 z-buffer)**实现的。
- z-buffer与颜色缓冲区有相同的尺寸大小,对于每个像素,其记录了距离相机最近的图元的z值,所以在渲染一个图像的某个像素时,需要将其z值与z-buffer中的值进行比较,如果z值更近,则使用该像素的z和color分别更新z-buffer和color-buffer。否则就不更新。因此这个算法与图元的渲染顺序无关。但是这种算法并不适合半透明物体,半透明物体需要等透明物体全部渲染完成之后才进行渲染,需要严格遵守从远到近的顺序进行渲染,而且不能写入z-buffer.
- 模板缓冲(stencil buffer)是一个离屏缓冲区(offsreen buffer),其尺寸与colorbuffer也一样,通常每个像素包含8bit。使用模板缓冲可以控制渲染到color-buffer和z-buffer的内容。
- 系统中所有的缓冲区在一起被称作帧缓冲(FrameBuffer)。
在实际渲染过程中,当前时间渲染的结果并不会马上出现在屏幕上,其目的是为了减少屏幕割裂(部分是已经渲染的,部分是上一帧的内容),因此一般都会使用双缓冲机制(Double Buffering),有的会使用三缓冲。这样每次渲染的结果会写入到BackBuffer上,而屏幕上显示的则是FrontBuffer,当BackBuffer渲染完毕之后,再与FrontBuffer交换,这个交换的时间通常发生在垂直同步阶段。
上述对引擎渲染管线进行了简单的介绍,其中有非常多的细节值得深入了解,由于文章篇幅,这里就不赘述,详细的可以参考RTR4第二章的参考资料,会有非常详尽的介绍。
在下一章介绍GPU硬件架构之前,我们首先介绍下不同设备平台上常见的GPU架构。主要包括IMR,TBR和TBDR。
IMR(Immediate Mode Rendering)
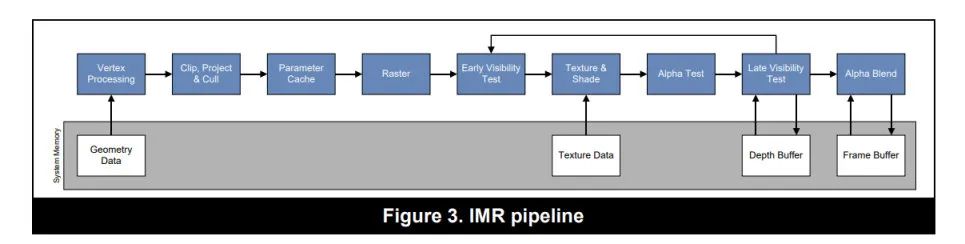
IMR是非常经典的渲染管线,也是桌面端常见的GPU架构。每个绘制的命令都会按照顺序从头跑到尾,执行完整个管线,最终将结果输出到FrameBuffer上。
优势
IMR的优势是整个管线没有中断,从头执行到尾,有利于提高GPU的最大吞吐量,最大化的利用GPU的性能;同时从Vertex到Raster的处理都是在GPU内部的On-chip memory上进行的,因此只需要很少的带宽(Bandwidth)就可以存取处理过程中的图元数据。所以桌面级GPU可以处理大量的的DrawCall和海量的顶点。
劣势
IMR是全屏绘制的,因此需要一个全屏的FrameBuffer,根据屏幕的分辨率和格式,这个buffer占用的内存可以很大,所以一般只能放到系统内存(DRAM)中,而在光栅化之后的阶段:pixel shading,depth testing,stencil testing,blending等都会需要跟系统内存进行交互,消耗大量带宽,所以桌面级GPU升级往往会升级更大的带宽和更大的缓存(L1和L2),但是对于移动端,这个是不可接受的。
TBR: Tile-Based Rendering
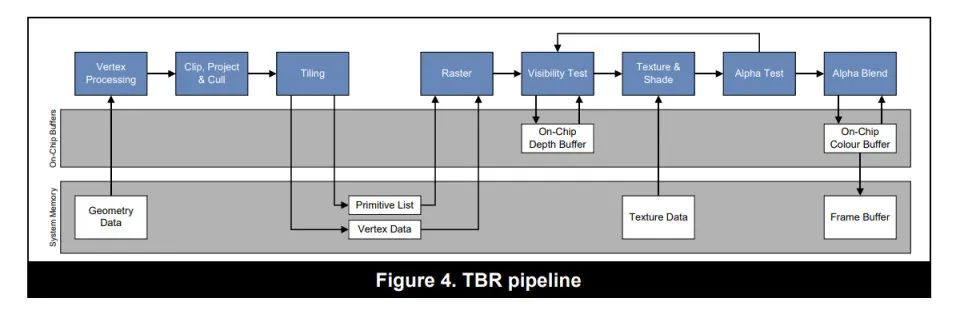
为什么需要TBR架构?
首先,对于移动端而言,功耗是一个非常重要的指标,功耗高意味着耗电,发热,降频,而带宽是功耗的第一杀手,大量的带宽开销会明显的增加功耗。移动端GPU的带宽远比不上桌面端GPU,而且无法像独立显卡一样独占大量带宽,因此移动端GPU使用TBR/TBDR架构。
TBR架构原理
TBR与IMR的不同之处在于TBR不是直接全屏绘制,而是将整个屏幕划分为一个个独立的Tile,GPU每次只绘制一个Tile,绘制完毕之后将绘制的结果写入到系统内存的FrameBuffer上。主要分为两步:
- 首先对屏幕划分Tile,PowerVR的一个Tile是32x32pixels,Mali中是16x16pixels;然后处理所有的顶点,生成一个TileList的中间数据,这个中间数据记录了每个图元属于屏幕中的哪个Tile。
- 第二步针对每个Tile执行像素处理过程,包括光栅化,像素着色器,融合处理等,等每个Tile处理完毕之后,将结果一起写入到系统内存中。
优势
TBDR架构最大的优势就是减少了系统内存的使用,即减少了带宽开销。由于每个tile足够小,因此其framebuffer是可以直接使用On-chip memory的。不仅仅是pixel shading,包括depth testing,stencil testing,blending等操作也都是在on-chip memory上进行的,大幅度的减少了像素处理阶段对系统内存的访问。而且tile中的depthbuffer和stencilbuffer是只针对于Tile内部有用,无需写入系统内存,进一步减少了带宽开销。
劣势
TBR需要首先划分Tile,然后生成tile list,再进行光栅化,更IMR相比,会存在明显的延迟(latency)。同时生成的TileList数据是需要存入系统内存的,会有带宽开销,而且顶点越多,计算压力越大,带宽消耗也就越大。像Tessellation这种操作再TBR下就非常昂贵。所以移动端对于顶点数量非常敏感,如果顶点数量过大的话,会导致性能严重下降。
TBDR: Tile-Based Deferred Rendering
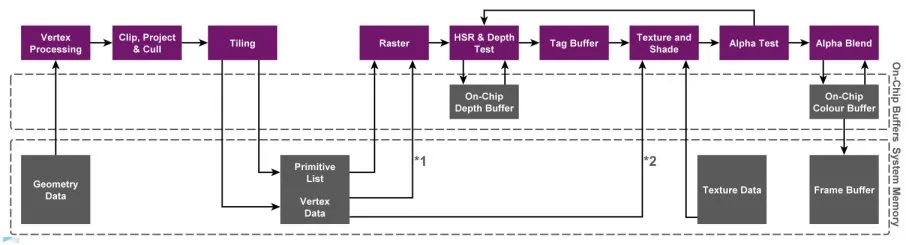
TBDR和TBR模式基本类似,位于的区别在于TBDR多了一个隐面剔除(Hidden Surface Removal)的过程,即上图中HSR&DepthTest。通过HSR,无论以什么顺序提交drawcall,最终只有对屏幕产生贡献的像素会执行像素着色器,被遮挡的部分会被直接丢弃掉。PowerVR使用的是HSR(Hidden Surface Removal) ,Andreno用的 Low Resolution Z(LRZ) ,Mali使用的是 Forward Pixel Kill(FPK),原理和实现各不相同,最终的目的都是为了避免执行无效的像素着色器。
总结
- IMR是桌面GPU的主流架构,Nvidia最新的显卡也支持了TileBased特性,但是它们的Tile的大小会更大。
- TBR是移动端GPU的主流架构,通过拆分Tile,减少带宽消耗。
- TBDR最开始专指PowerVR,光栅化之后不是立即渲染,多了一个隐面剔除的步骤,后来Andreno和Mali也提出自己的隐面剔除方案,所以目前移动的GPU基本都是TBDR的架构。
- 更多的GPU架构绘制过程可以参考文章:GPU Framebuffer Memory: Understanding Tiling。
