
游戏性能优化
最近在Youtube上看到一个很不错的讲游戏性能优化的系列视频,花了几个小时学习了一下。作者从游戏性能优化的准则,优化的方向做了较为详细的介绍,以及介绍了性能分析工具的使用,并结合Unity和Unreal的示例场景来实际分析和优化游戏性能。由于视频时长限制,很多方面讲解的不是很深入,这里对视频里印象较深的部分做一些总结,同时也作为性能分析的一个学习资源笔记,后续有时间可以针对各个方面进行更深一步的探索。
游戏优化准则
谁来优化?
游戏开发实际是策划,美术,程序等各个不同职能的人来共同完成的,那么对于游戏的优化而言,作者认为不是由某个人来完成,而是每个人都需要了解和参与。美术需要知道哪些能做,哪些不能做,哪些效果需要,哪些效果没那么重要。程序需要知道哪些可以做,哪些做不了,哪些可以做的更好。
游戏性能优化是一个非常大的课题,实际过程中不同的项目,由于美术资源,玩法,画面效果,以及设备平台的不同,甚至是引擎的不同,需要面对的优化问题可能都是不一样的,因此没有所谓的统一的优化方法,而是需要具体问题具体对待。
下面这句话是贯穿整个系列视频的指导准则
**先分析,再优化**
这句话听起来也很好理解,我们在面对性能问题,做性能优化之前,需要首先对游戏的性能做一个全面的分析,这就好比看病之前都先诊断一样,只有找到性能的卡点和主要的消耗,才能够对症治疗。而且我们关注的往往是那些占比很大的部分,针对他们进行优化,才能够立竿见影,不然很有可能优化了半天,画面效果损失了不少,性能提升却微乎其微。
游戏优化指标
我们常用的游戏性能评估指标就是帧率FrameRate,也就是FPS,它的意义是游戏每秒钟跑多少帧,帧率越高,自然性能也就越好。还有另一种评价方法就是帧时间FrameTime,也就是游戏渲染一帧需要花多少时间,FrameRate和FrameTime虽然评估的内容都差不多,但是这两种的直观感受对应的实际意义却不一样。
从下面这张图可以看到,FrameRate和FrameTime的变化率是不一样的。帧率较低的时候,如从10FPS变化到20FPS,和从100FPS变化到110FPS,虽然帧率都增加了10FPS,但是前者的FrameTime减少了50ms,后者则只减少了不到1ms。这两个性能优化的幅度是完全不能相比的,所以我们实际做性能优化的时候,更加看重的是FrameTime,也就是一帧所花费的时间。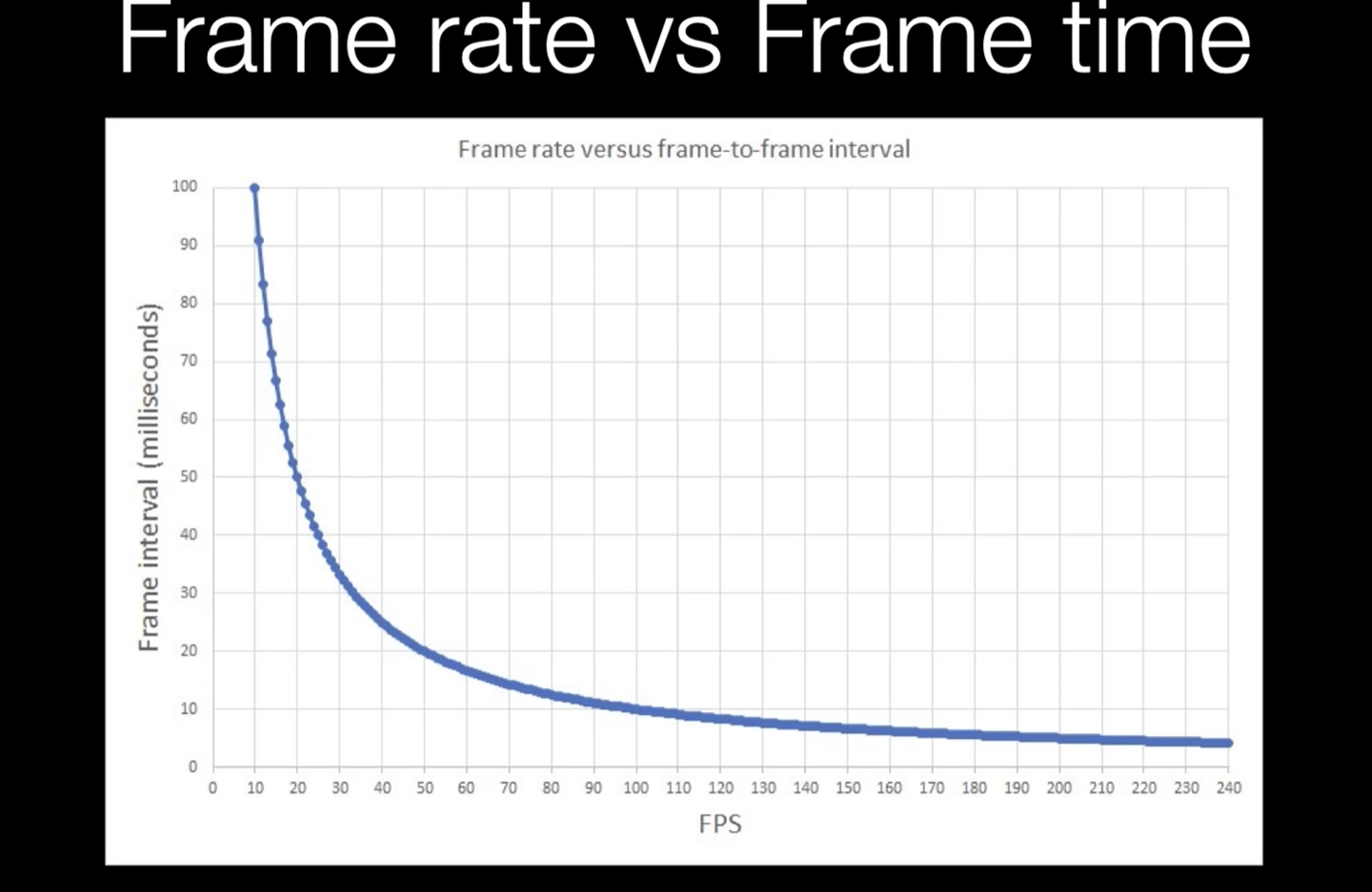
渲染管线
首先是游戏渲染管线的选择,渲染管线主要分为Forward和Deferred。当然,实际的渲染管线还有和很多中的变种。Forward Rendering中每个物体只需要渲染一次,每个模型都进行独立的关照计算。Deferred Rendering一般分为两个pass,第一个pass是将所有的物体都渲染到GBuffer上,第二个pass在GBuffer上执行逐像素的光照。
Forward和Deferred Render Methods有各自的优势和劣势,具体的详细内容可以开一篇专门的文章来介绍了,这里我们关注的是不同的设备平台和游戏类型上选择合适的Render Method。经验上来说,Forward Rendering适合低端的移动设备和简单的游戏场景,而Deferred Rendering则适合高端设备以及复杂的游戏场景。现代游戏引擎一般同时使用这两种方法:针对不透明物体使用Deferred而针对透明物体使用Forward。这里需要注意的是,虽然Deferred Rendering相对于Forward计算光照更省,但是如果场景中存在大量的光源的话,也还是会有非常大的性能消耗的。
在做优化之前,首先需要确定目标,包括游戏需要运行在哪些平台上?预期的游戏帧率多少?一般而言游戏帧率一般在30或者60,对于实时对战或者FPS游戏,则预期帧率可能更高。我们需要对于硬件设备的abilities,也就是硬件性能需要有所了解,比如支持的模型顶点的数量级,DrawCall的数量级等。
在实际测试性能的过程中,需要尽可能的排除其他因素的影响,控制变量去比较。在Unreal和Unity中,需要脱离Editor独立Build游戏来运行测试,同时需要控制相机位置和视角等,对比前后都要固定。如果需要对比动态效果,比如TOD系统,还需要固定时间点来进行对比。总之测试的关键就是:
**尽可能的排除其他因素,控制变量**

性能分析
前面说过,做性能优化之前先做性能分析,游戏性能分析的结果有两种:CPU Bound或者GPU Bound。搞清楚性能瓶颈是在CPU还是GPU非常重要,因为假如是CPU Bound,那么不管如何去优化GPU性能,对于最终的帧率也不会有所提升,因为始终是GPU在等CPU完成工作。反之GPU Bound也是一样。
那么如何判断是CPUBound还是GPUBound呢?对于商业引擎会提供TimeStats,用于显示各个阶段的耗时,可以直观的对比CPUTime和GPUTime来判断是哪种Bound。如果引擎没有提供这些数据,那么一种比较快速的判断方法便是降分辨率。也就是通过降低渲染分辨率,然后观察FrameRate的变化,如果降低分辨率会提高FrameRate,那么说明就是GPUBound,否则是CPUBound。因为降分辨率只会影响GPUTime。
当然还有一些其他的方法可以判断是CPUBound还是GPUBound,具体可以参考文章1和文章2。
如在Unity中,通过Profiler的标志可以判断Bound类型:
- 如果是Gfx.WaitForCommand,这表示渲染线程在等待渲染命令,可能是CPUBound.
- 如果是Gfx.WaitForPresentOnGfxThread, 这个表示主线程的渲染命令已经准备好了,在等待GPU进行渲染,表明是GPUBound.

CPU Bound
造成CPU Bound的一种情形就是DrawCall的数量太多,因为CPU需要为每个DrawCall向GPU发送渲染命令,非常耗费时间。所以优化的方向便是降低DrawCall数量,第一种方法就是减少渲染的物体数量,各种Culling的方案。当Culling完成之后,场景中的物体仍然比较多时,比如树木,植被,石头等这些,则可以通过Batching和Instancing等批处理的方法来减少DrawCall数量。批处理又分为离线和实时,比如离线就将一些小的,材质相同或者相近的模型合并成为一个大的模型,这样便可以减少物体的数量。实时的则是在运行期对可见的物体进行合批。具体使用哪种方法可以根据游戏场景的类型来做选择。
当然造成CPU Bound的原因很有可能跟渲染无关,比如一些动画,物理,逻辑相关的处理也会消耗CPU时间,具体这些就需要找相关的人员进行排查了。
GPU Bound
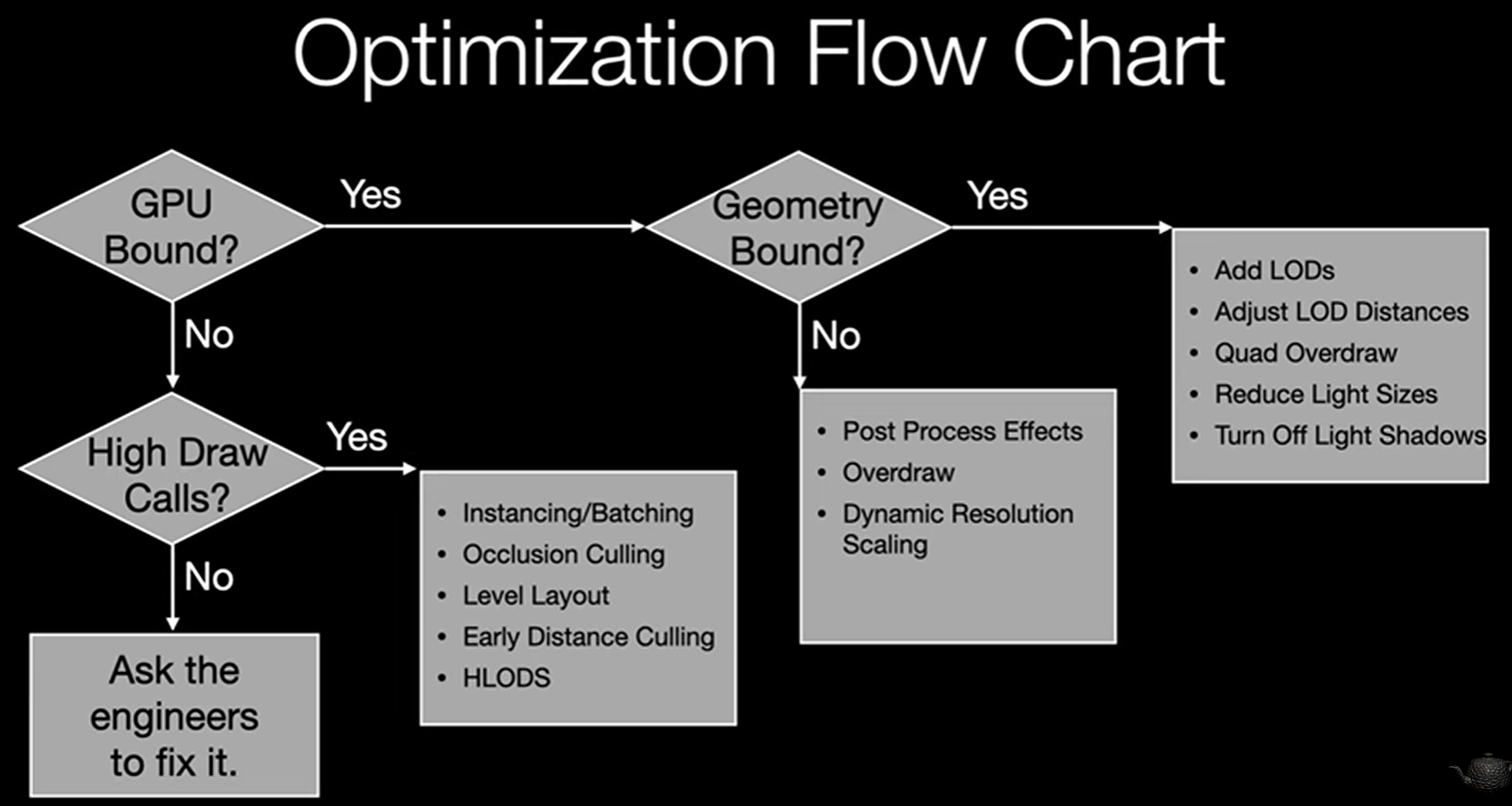
下面这张图介绍了主要的优化思路。
首先分析是否是GPU Bound,如果不是,则根据上述CPU Bound的优化思路;如果是,则分析下是否是Geometry Bound,也就是场景中渲染的几何数量是否过多。
- 如果是Geometry Bound,则需要减少几何的数量,比如采用LOD,调整LOD的切换策略,减少细小三角形数量,降低光源的大小,关闭光源的阴影。
- 如果不是Geometry Bound,则需要考虑优化其他的GPU开销,比如各种后处理的效果(TAA,AO,Motion Blur等等),减少Overdraw,或者降低渲染的分辨率等。
LOD
传统的LOD应该都很熟悉,在物体不同的相机距离/屏幕大小的时候,切换不同的GeometryData。LOD的好处不仅是减少了顶点的数量,同时还减少了Overdraw。在传统的LOD基础上,还有HLOD算法。HLOD相比传统的LOD在于它下级的LOD同时合并了上级的多个LOD模型,构成一个树状的结构,不仅减少了几何的数量,还同时减少了物体的数量。UE5中的Nanite技术是一种更加灵活高效的LOD技术,它通过构造ClusterLOD层级,能够对物体的不同部分使用不同层级的LOD数据,配合高效的剔除算法,能够尽可能的减少几何绘制的数量。
Quad Overdraw
Quad Overdraw简单来说就是GPU在做渲染的时候,每次并不是只渲染一个Pixel,而且按照Quad,也就是四个像素一起进行渲染。那么一个三角形在渲染的时候,其Edge上很有可能一个Quad只覆盖了其中的一个Pixel,如下图左侧,但是其他的三个Pixel也需要进行渲染,这就造成了浪费,也叫做Overdraw。比较极端的例子是右侧的图示,如果一个三角形本身就要比一个pixel的大小还要小,那么其也会渲染一个Quad,如果场景中这种细小三角形很多的话,则造成的性能浪费的问题会是非常严重的。
关于Quad Overdraw的详细介绍可以参考这篇文章。


Light Optimization
场景中灯光的数量对于游戏性能也会造成非常大的影响,在Forward管线中,每个在灯光范围内的模型都会产生渲染开销,而在Deferred管线中,灯光渲染的开销则取决于其在屏幕上的投影大小。所以从本质上来说,减少灯光的数量以及减少灯光的大小会对游戏性能有积极的影响。
Shadow Optimization
跟灯光相关的另一项就是阴影。阴影的开销在渲染管线中一般都占比比较大,尤其是点光源的阴影,因为它需要渲染六个方向的shadowmap。因此对于Point Light或者Spot Light我们可以关闭其投射阴影,或者对于静态模型可以将其阴影烘焙下来。
对于方向光的阴影,优化的方向则主要从阴影范围和阴影精度等方面来进行。比如CSM算法,根据玩家的距离来调节阴影的范围和精度,由近到远精度由细到粗。
Post Processing Optimization
最后就是后处理相关的效果。AA,AO,DOF等等。在实际测试的过程中,SSAO一般会有比较高的时间消耗,我们在优化的过程中,需要对这些效果进行开关测试,看看其是否真的是有效的,或者说是真的有必要的,值得我们付出相应的时间消耗。所以这部分实际上是一个Trade-Off。
Shader Optimization
Shader是GPU实现效果的本质,所以优化Shader对于优化GPU性能来说非常重要。首先看下Shader性能优化的几个方面:Optimize Texture Sampling, Do Less Math, Do Math in the Right Place。
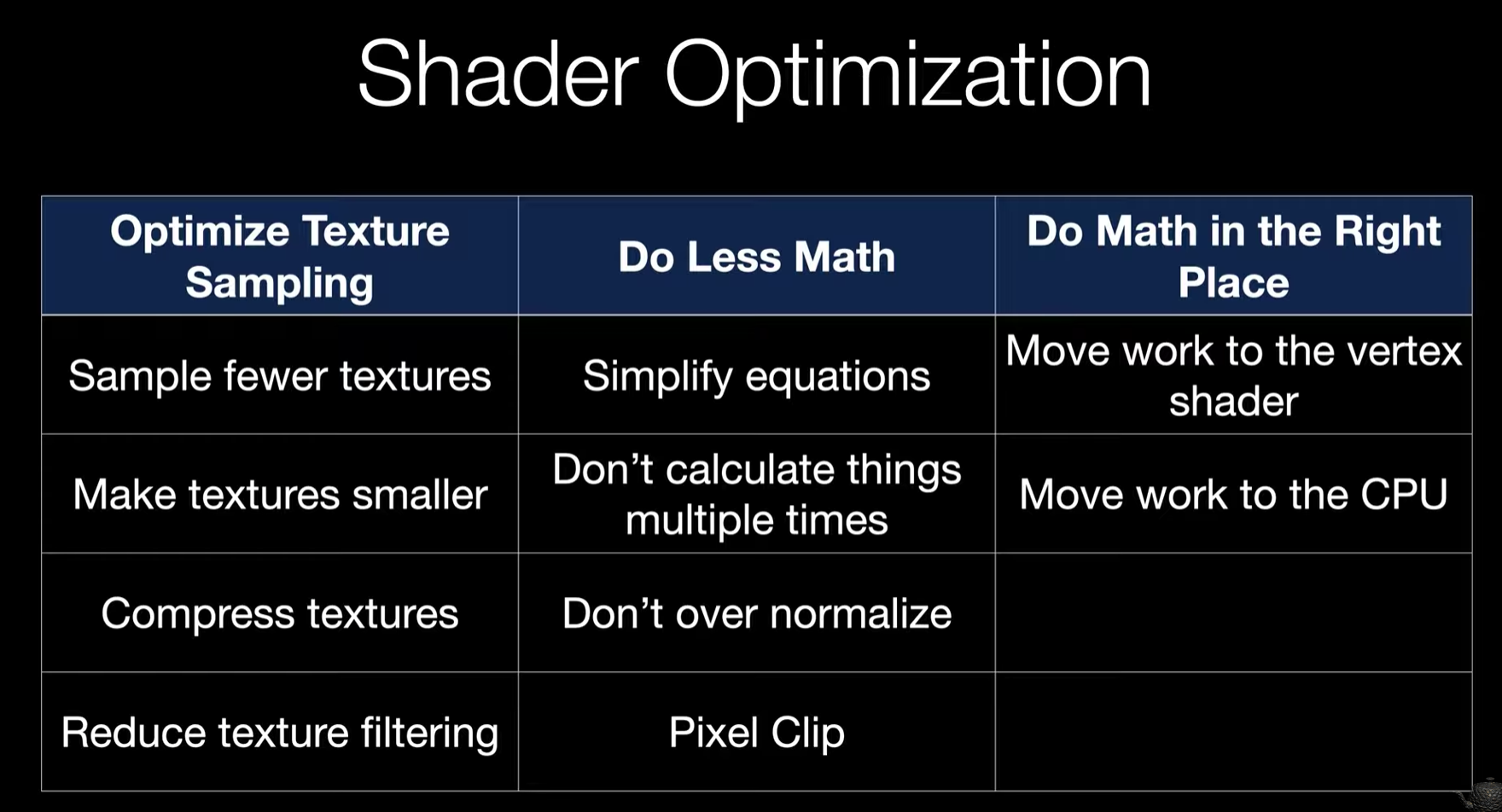
Optimize Texture Sampling
贴图采样是Shader中最耗时的操作,相比较数学计算而言。因为当GPU需要采样贴图的时候,首先会计算当前合适的mip level,然后从VRAM中发起读取的申请,等待读取的数据返回。GPU在等待数据返回的过程,会做一些其他的工作,如果没有其他工作可做,那么就会直接wait。
所以优化贴图采样的操作主要包括以下几个方面:
- 减少贴图数量。贴图的数量越少,采样的次数越少,那么肯定性能越好,一般减少贴图数量的方法就是pack贴图,也就是将不同的贴图pack到同一张贴图上,通常采用的方法是pack到不同的通道,比如pack normal和roughness,将normal数据pack到贴图的RGB通道,roughness数据pack到A通道,则将原来的两张贴图变成了一张,那么在shader内进行贴图采样的时候,也只需要采样一次,然后unpack出normal和roughness即可。当然更加直接的方法就是去掉贴图,比如对于一些不重要的,或者细节较少的物体,直接去掉normalmap,往往不会损失太大的效果,但是性能提升却是立竿见影。
- 减小贴图大小。贴图大小影响性能的原因在于GPU在获取贴图的时候会有一个cache,从cache中获取数据会更快,而贴图大小往往直接影响cache的命中率,因此间接影响游戏性能。而且更大的贴图对显存和带宽都会带来负面影响。因此在保证效果的前提之下,使用更小的贴图是一个更好的选择。
- 贴图压缩。贴图压缩和减少贴图大小的效果类似,可以有效的减少贴图占用的显存和读取的带宽。
- 减少贴图过滤。高级的贴图过滤(如双线性、三线性、各向异性过滤)需要对多个纹理像素(Texel)进行采样并混合计算,会增加采样的复杂度,同时对内存带宽,TextureCache等都会造成负面影响。

Do Less Math
减少数学计算,这个很好理解,计算越复杂,性能消耗自然也就越高。减少数学计算主要从以下几个方面:
- 简化计算。也就是采用简单的算法来替代复杂的算法,这种简化一般需要优化人员对代码的逻辑比较熟悉,采用更加简单的计算公式,以达到近似或者类似的效果。
- 减少重复计算。在shader计算中,尽可能的复用前面的计算结果,减少重复计算,这点不光是计算上,其他的操作也是一样,比如上面说的贴图采样。耗时的操作只需要计算一次,后续复用结果。造成重复计算往往在某些循环的逻辑中,因此需要考虑,是否可以将重复的操作提到循环之外来进行?应提尽提。
- 避免过度Normalize。normalize计算在shader中属于计算复杂度高的操作(因为涉及到开方的操作)。很多情况下,向量本身已经是单位向量(例如法线向量、切线向量通常在建模或预处理阶段已归一化),此时再调用normalize就是冗余操作。此外,若同一向量在 Shader 中被多次使用,重复normalize会重复消耗计算资源,合理的做法是计算一次后复用结果。
- 使用Pixel Clip。Pixel Clip(像素裁剪) 是指在像素着色器阶段对不符合特定条件的像素进行丢弃或屏蔽的操作,通常通过 clip() 函数(HLSL)、discard 关键字(GLSL/HLSL)或类似机制实现。其核心作用是在像素被绘制到帧缓冲区之前,提前剔除不需要显示的像素,从而优化性能或实现特定视觉效果。
对于需要部分透明(非半透明)的纹理(如植被、网格图案、破洞布料等),可以通过像素裁剪直接丢弃 alpha 值低于阈值的像素,避免复杂的混合运算。对于完全不可见的像素(如被遮挡、超出视口或不符合逻辑条件的区域),提前裁剪可以避免后续的深度测试、模板测试、颜色混合等操作,减少 GPU 的计算负担。
Do Math in the Right Place
同样的计算方法,在不同的地方计算,性能有可能会有非常大的差异。一个简单的例子就是逐顶点光照和逐像素光照。逐顶点光照中,每个顶点计算光照结果,然后在PS阶段只需要进行插值即可,而逐像素光照则是在每个像素都进行光照计算,这两种方法的计算量差别是不可同日而语的。不同类型的计算在哪里进行可以参考以下的表格,给出了每种计算的合适场景。如果某个计算是耗时的或者某个计算的次数很多,那么我们都需要好好思考下这个计算具体放到哪里比较合适。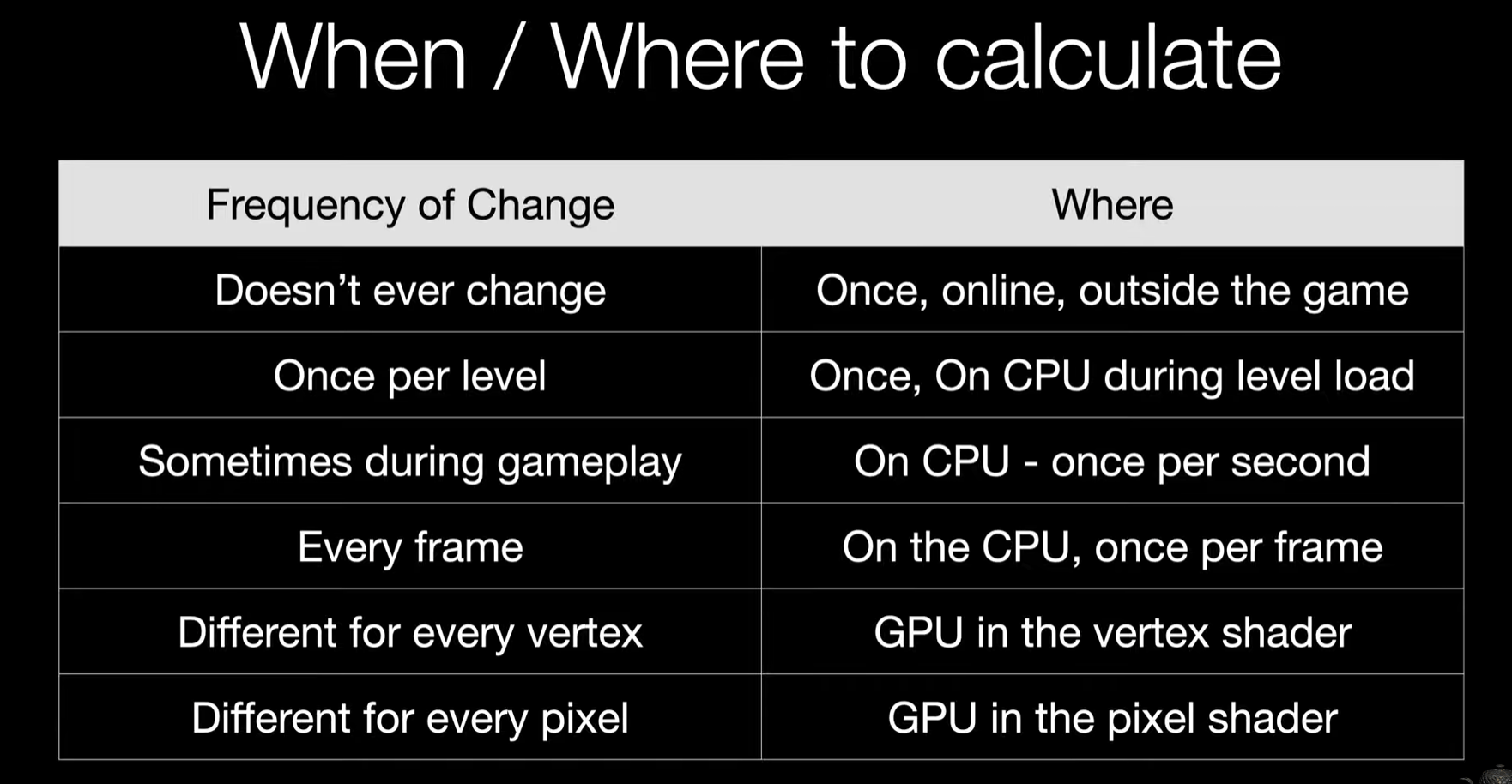
结语
以上对游戏性能优化的各个方面进行了简要的介绍。游戏优化是一个非常大的课题,简单的一两篇文章很难总结完全,而且做优化也是一个非常依靠经验的活,需要大量的实践,不断的总结,始终要记住:
实践是检验真理的唯一标准。
参考文献
