
C++内存管理之std::alloc源码分析
书接上回。侯捷老师的教程里对G2.9的std::alloc的运行模式和源码都进行了非常精彩的讲解。虽然这个allocator的历史比较久了,但是其中的设计思想对于后续的内存分配还是有比较重要的参考意义。这里就老师课程中的内容做一些总结记录。
std::alloc的运作模式
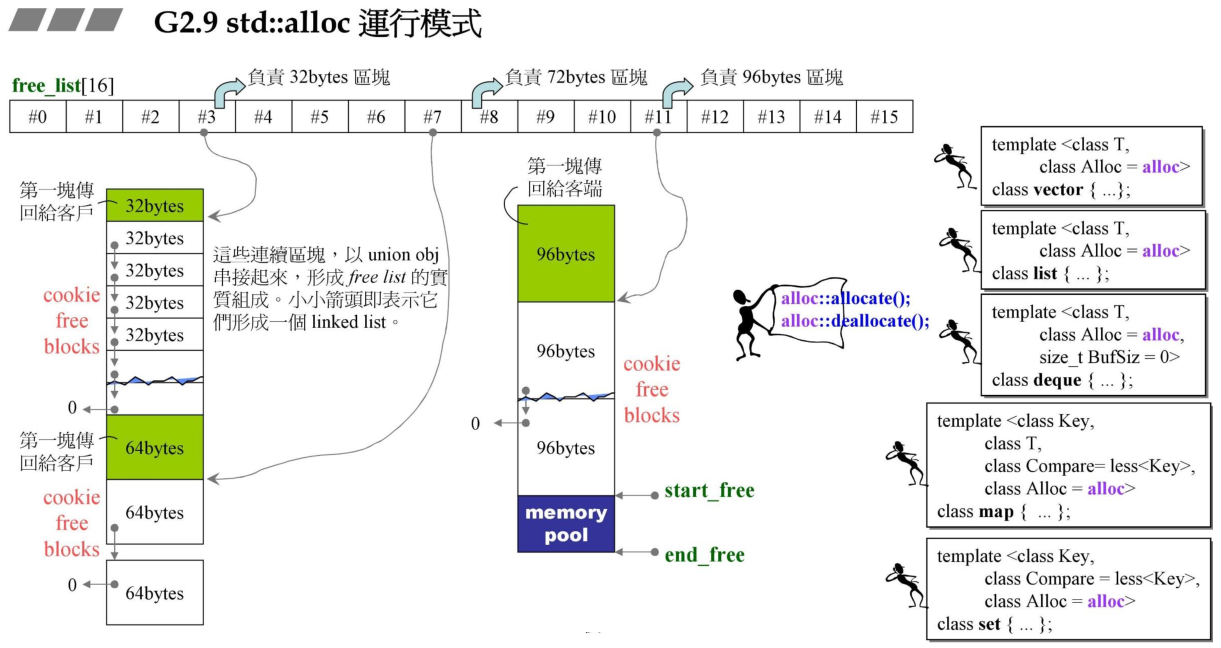
上图表示了std::alloc的运作模式示意图,std::alloc使用了一条16个元素大小的数组来管理链表,不同索引的元素管理不同大小的链表。其中#0链表记录的是最小的8个bytes的链表,而#15链表记录是最大的128bytes的链表,相邻的链表元素大小相差8bytes。这里需要注意的是:该链表仅维护分配128Bytes以内的内存块,大于128Bytes的则将直接使用malloc直接分配空间。
嵌入式指针
这里每个细分的区块使用的嵌入式指针来节省内存的使用,每个被管理的自由区块头部使用嵌入式指针指向其他的链接的区块,而一旦区块被分配给用户,那么这段内存就可以直接被使用,因此不会造成内存的浪费。这种嵌入式指针的思想在很多的分配器中都有使用。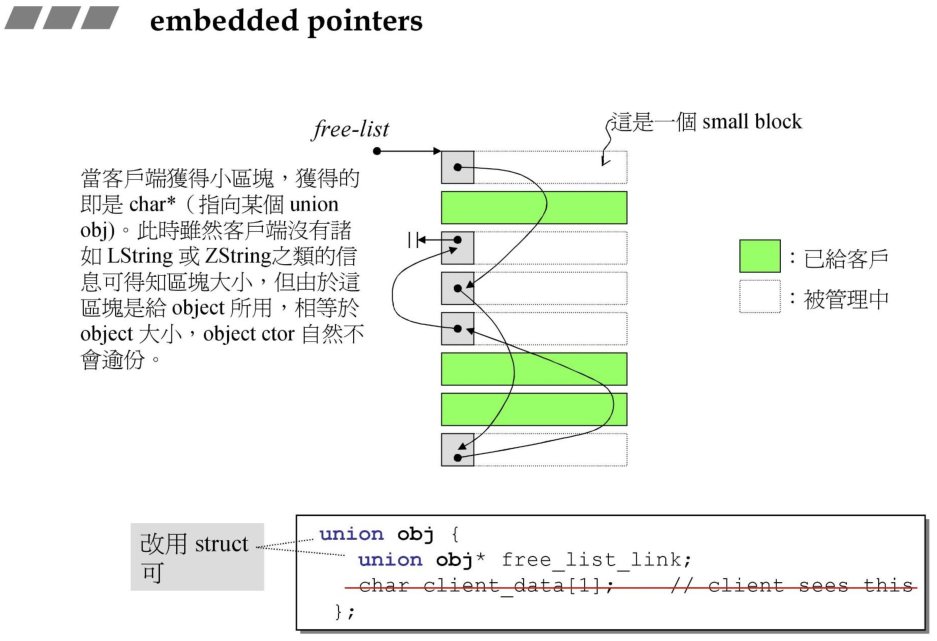
以下直接通过截取PPT内容来看下std::alloc的内存分配
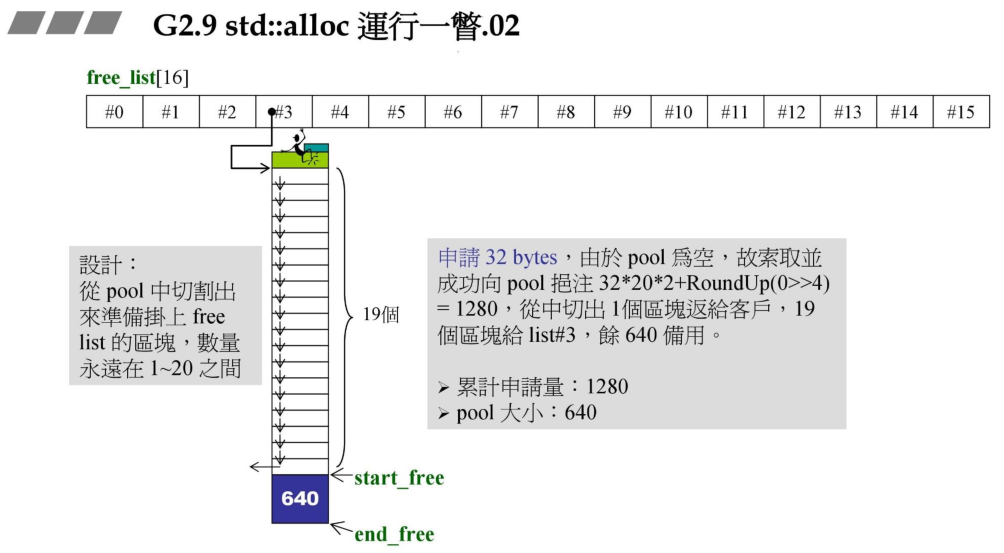
1、在申请内存的时候,如果对应大小的元素列表没有可用的内存(pool)为空,那么便从系统获取对应的区块大小乘上20,并乘上2,再向上RoundUp,分配完成之后,拿出一块给用户,其余19个挂接到对应大小的元素链表上。目前累计申请量1280Bytes,pool大小为640Bytes,通过start_free和end_free两个指针指向空闲的空间。
TIP: 对于每个从系统申请内存块的时候,都是一次申请20个,20是经验值,然后再额外获取一倍的大小的内存,然后再通过roundup,注入到pool中备用。也就是32的内存块实际分配的是 32 * 20 * 2 + RoundUp.
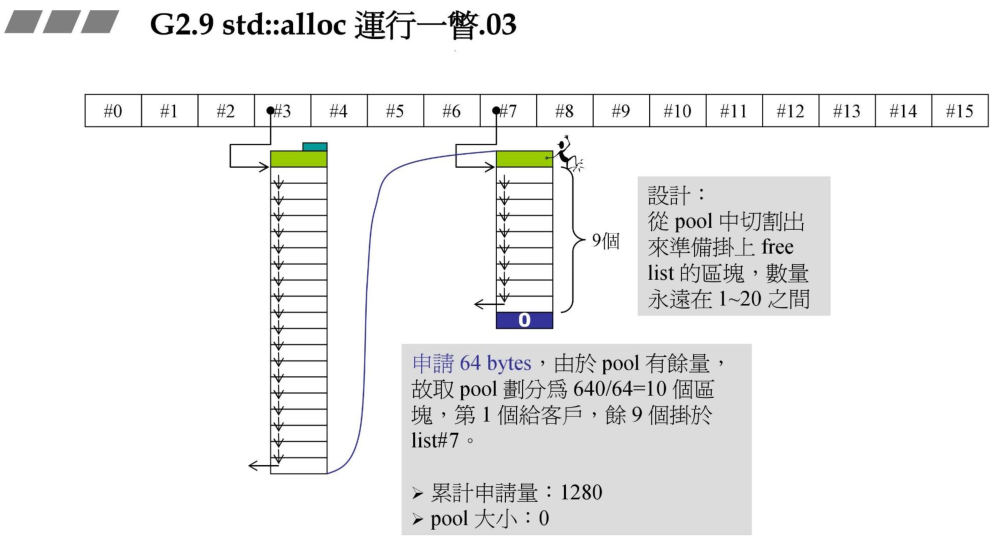
2、现在用户需要申请64Bytes的内存块,64bytes对应的#7链表为空,由于pool有余量,便从pool里分割 (640Bytes / 64Bytes = 10)个区块,分配第一个给用户,其余的挂接再#7链表中。此时pool大小为0.
每次新增的区块的大小最多为20个,Pool内存不足20个的时候,能分配多少是多少。
3、继续分配,当用户申请96bytes时,由于96bytes对应的链表为空,而且pool为空,于是想系统申请内存,按照上述的规则,申请的大小为96 * 20 * 2 + roundup(1280 >> 4)。第一块返回给用户,其余的挂接到#11链表,现在累计申请5200 Bytes,pool的大小为2000。
roundup的大小为已经申请的内存大小>>4,也就是除16.这个算法也是经验值。
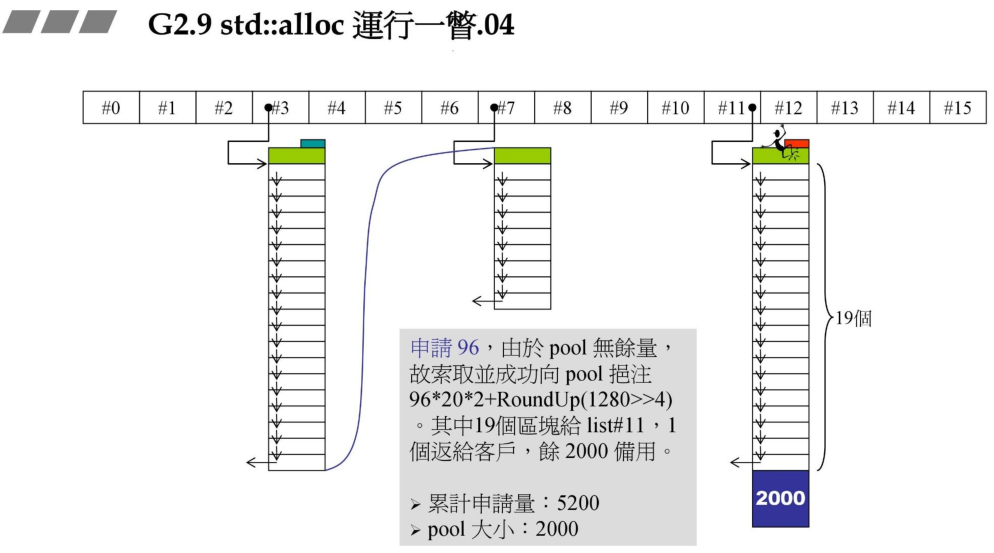
4、当用户申请88Bytes的大小,从pool中分配20个区块,返回一个给用户,其余19个挂接到链表中,pool余量为 2000-88*20 = 240Bytes.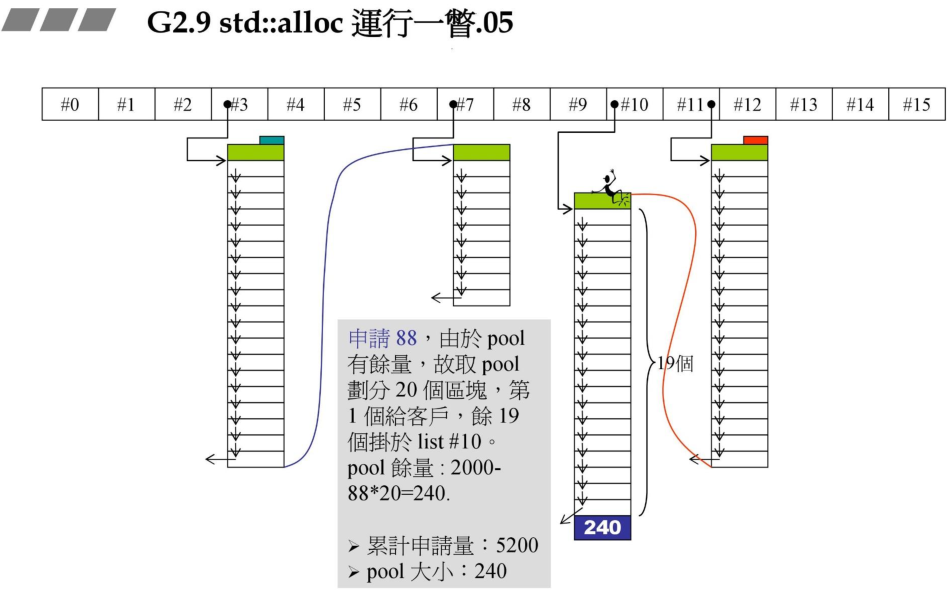
5、然后用户连续三次申请88Bytes,则直接从#10链表中取出返回给用户即可。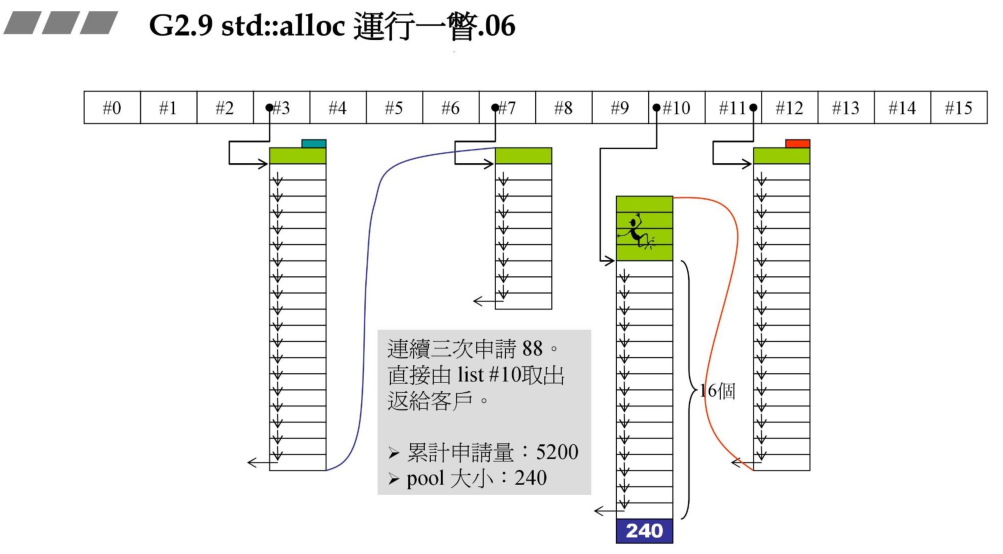
6、申请8bytes的时候,从剩余的pool中分割20个区块,然后返回一个给客户,其余的挂接到#0链表中,pool余量为80。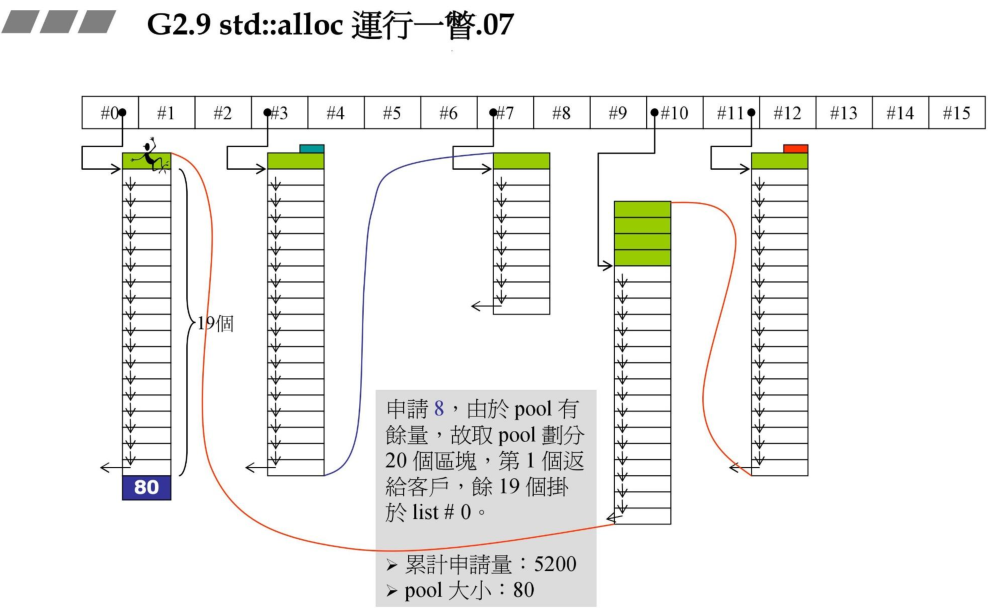
7、当用户申请104bytes时,由于pool的余量都不足分配一个区块,这里的操作是先将pool剩余的内存按照大小计算,挂接到对应的内存大小链表上。计算的链表节点为#9。然后向系统申请内存大小 104 * 20 * 2 + RoundUp.分配第一个给用户,其余的挂接到#12链表。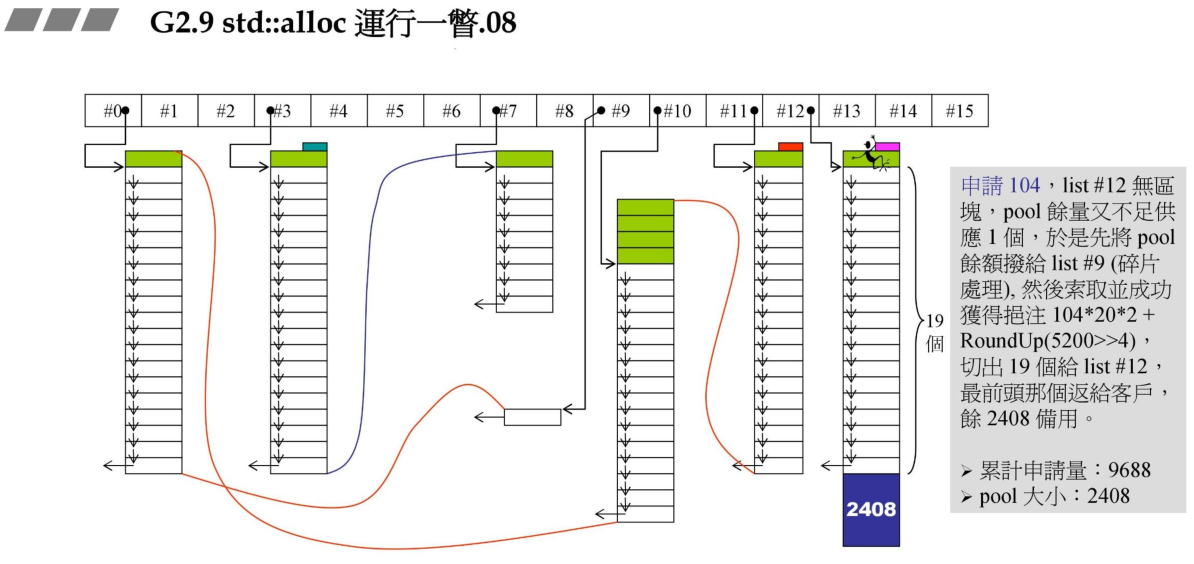
8、以上是假设系统内存可以一直分配,但是如果系统无法分配内存时,则申请一个特定大小的内存时,需要从邻近大一点的的链表中取出元素回填pool,然后从pool正申请一个内存块返回给用户。如果邻近的没有,则继续向上索取。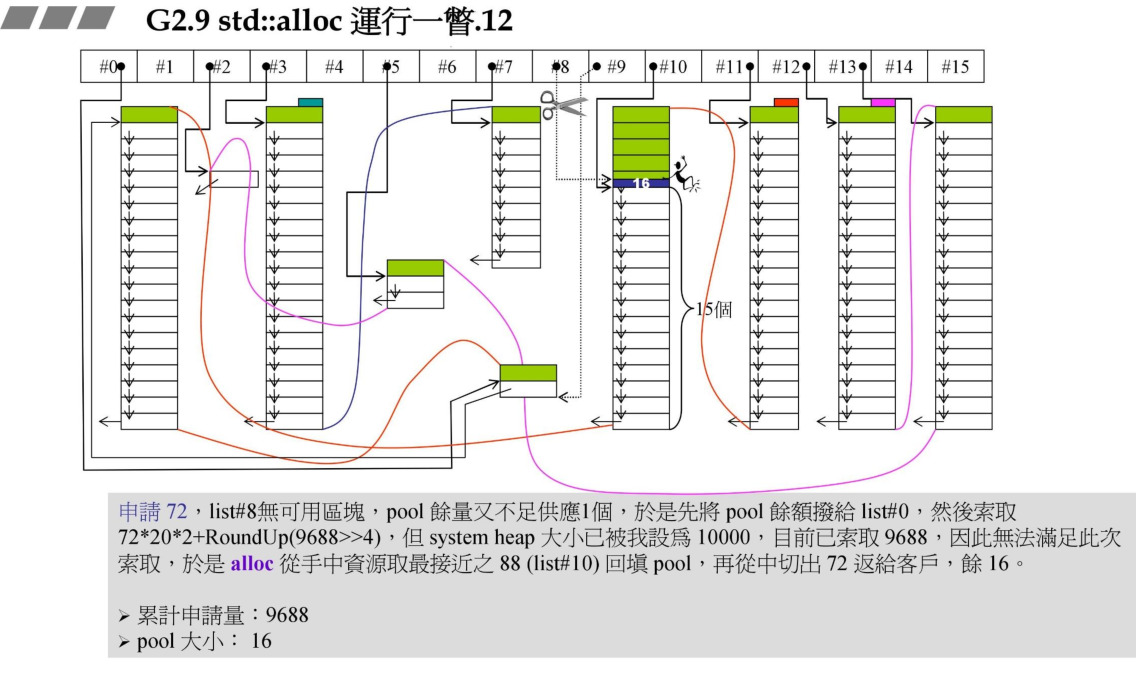
std::alloc源码分析
这里首先从第二级分配器的代码开始,该分配器的名字叫做__default_alloc_template,这里定义了ROUND_UP函数,里面将使用的字节数bytes做对齐,对齐到__ALIGN,这里的_ALIGN为8Bytes。类内部定义了union free_list_link,这个就是前述说的内嵌指针。free_list是一条静态数组数据,管理着16条链表,start_free和end_free分别指向该内存池的头和尾部。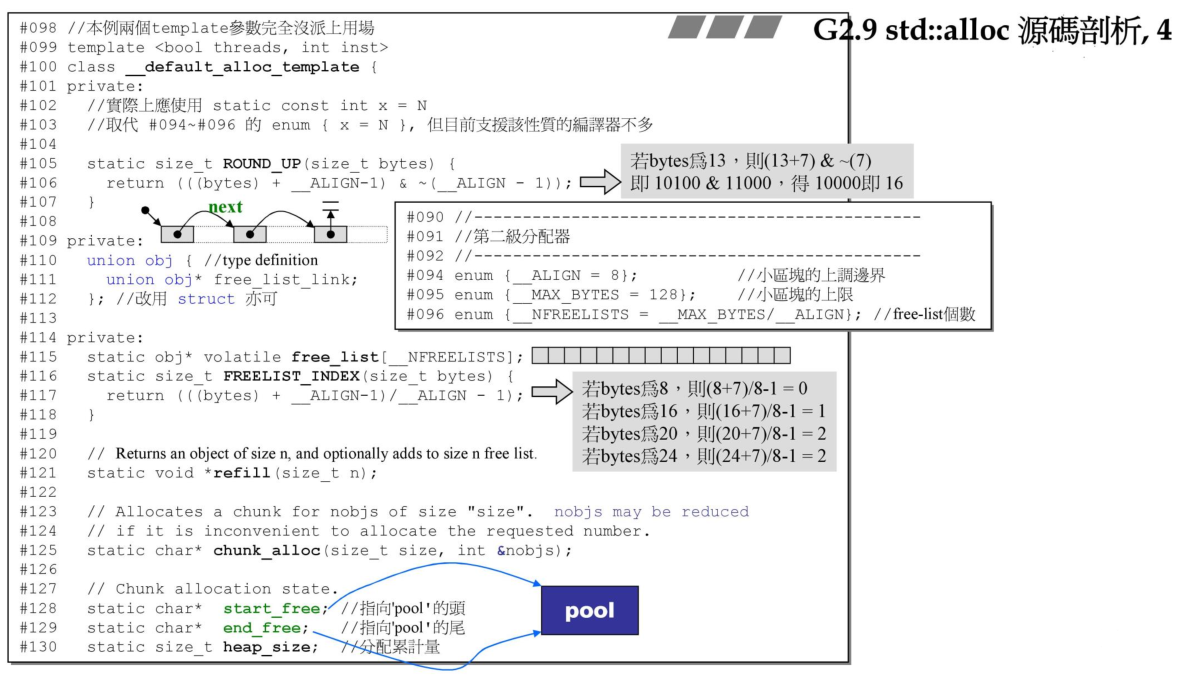
首先看下allocate函数,首先定义的my_free_list指向的是静态链表数组中的任何一个,*my_free_list则是取出free_list某个元素的值,该值指向一条分配内存的链表,所以这里的my_free_list为二级指针。
首先通过判断用户分配的大小是是否超过了内存管理的最大大小(128Bytes),如果超过了则直接调用malloc_alloc::allocate(),也就是第一级分配器。如果小于128Bytes则继续。
代码143行是通过分配的内存块大小来定位链表的索引,FREELIST_INDEX就是索引定位函数。判断下对应索引的链表是否为空,如果为空,则调用refill来分配内存;如果不为空,则说明对应的链表中还有空闲的内存块,直接将空闲的内存块返回即可。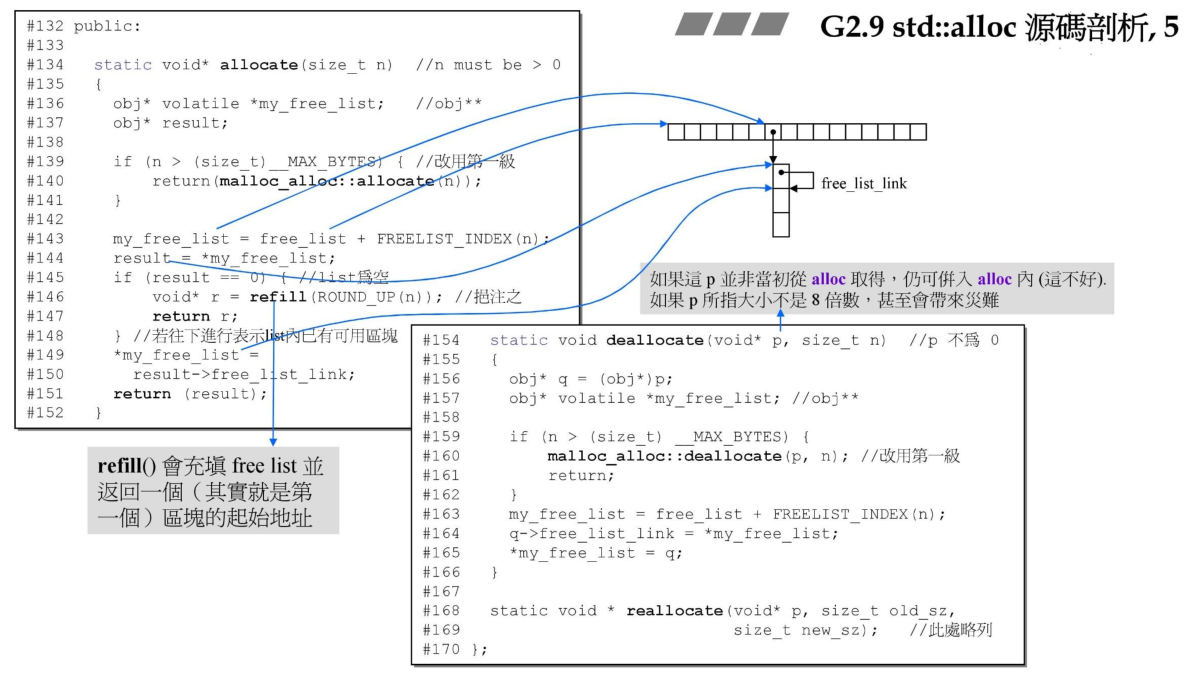
下图形象的说明了上面的分配过程。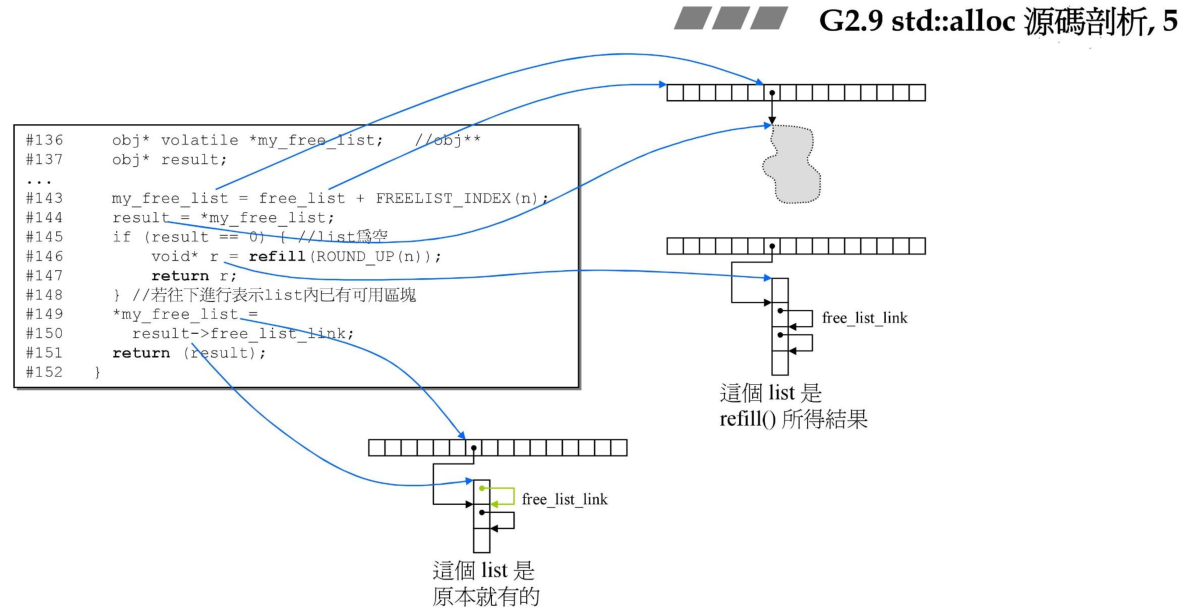
然后观察下deallocate函数,这里释放的逻辑就很简单了,找到释放的内存块所在的链表索引,然后将内存释放后挂接在对应的链表上即可。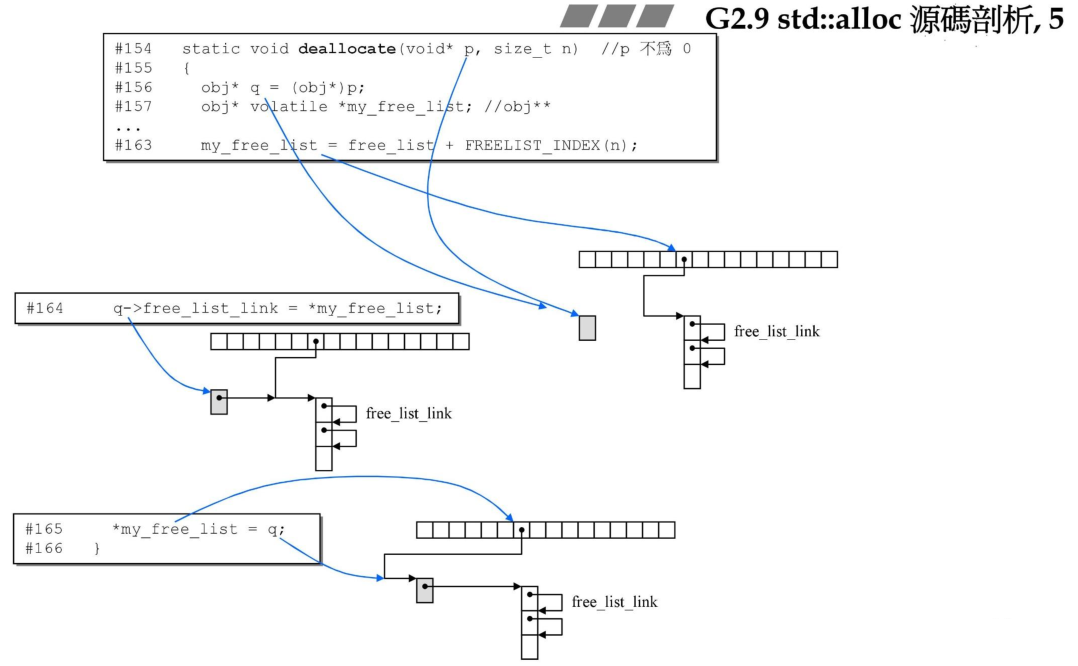
最后来分析下refill函数,这个函数是std::alloc的核心。在此之前,查看下chunk_alloc函数.
chunk_alloc在最开始计算了一些需要的值,包括需要分配的总的字节数,pool里剩余的字节数,然后判断剩余的内存空间是否能够满足当前的分配的20块的大小,如果满足,则直接分配即可。如果不满足,则看下pool空间是否满足至少分配一块内存块,如果可以,则计算出可以分配多少块(这里nobjs是传引用的,所以可以返回实际分配了多少块)。如果连一块都不能分配了,则需要向系统来申请内存空间,首先将pool剩余的内存物尽其用,分配到对应的链表上。然后调用malloc来分配需要的内存空间大小,如果分配失败,则表示系统可用内存不够,那就需要在已经有的内存上划分出来可用的空间来利用了。
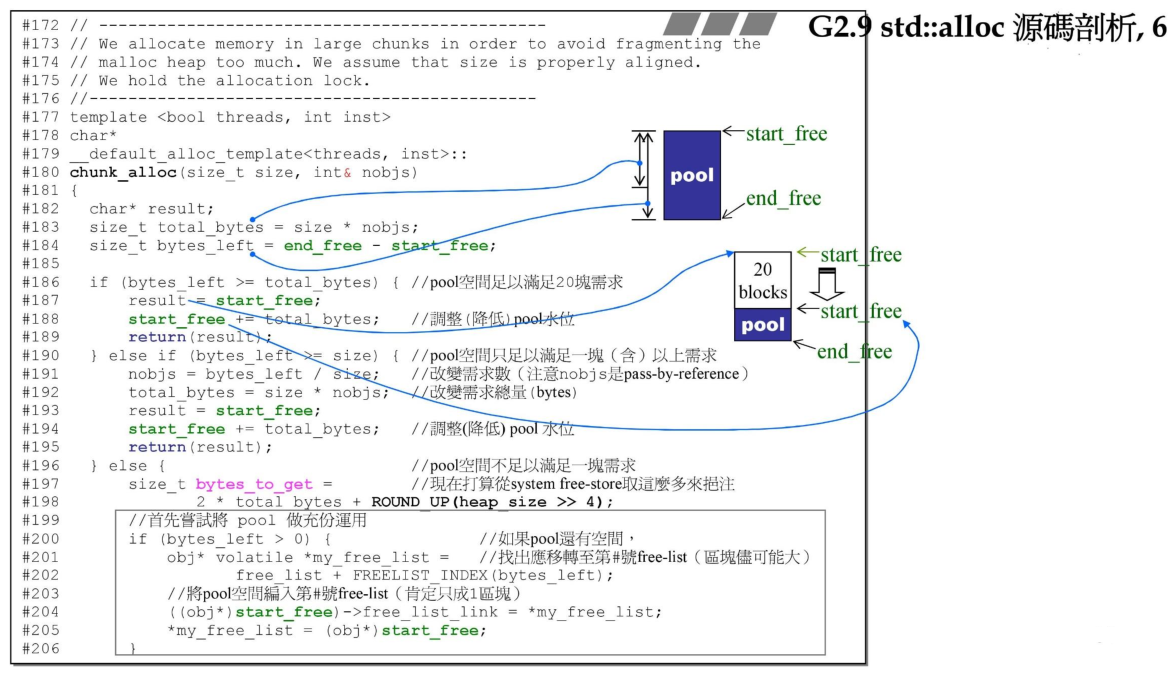
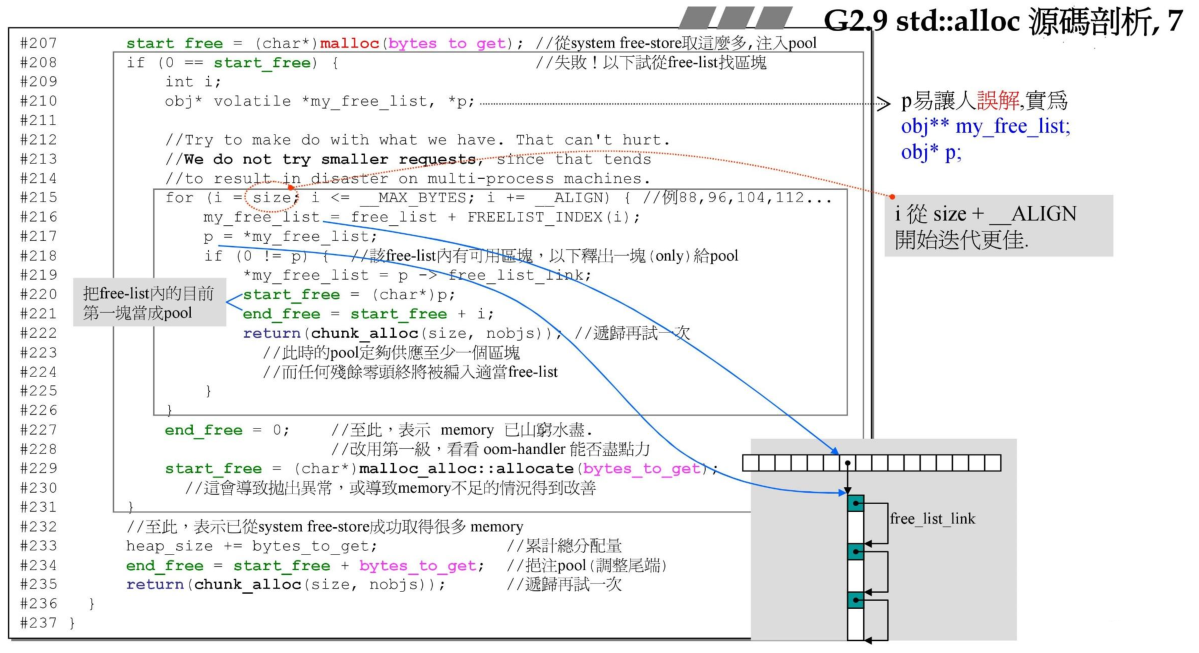
然后再回过头了看refill函数,可以看到首先设置需要分配的内存块的个数为20个,然后调用chunk_alloc函数,这里的nobjs是传引用的,因此可以获取实际分配的内存块的数量,chunk_alloc返回的chunk指针则是实际分配的内存指针。
如果只分配了一个(nobjs==1),则直接返回给用户即可。如果nobjs数量大于1,则将多余的内存块建立链表链接,挂接到对应的链表数组里。
以上便是std::alloc的内存管理的详细过程,其中有很多的优化技巧和经验值得仔细体会。
